



一.标题
基于多阶段机器学习的KPI异常检测与相关性模型研究
二.时间
2020年
三.关键字
- 多类型KPI Multi-type KPIs
- 异常检测 Anomaly Detection
- 根因定位 Root Cause Location
- 机器学习 Machine Learning
四.作者
靖宇涵
五.文章来源
北京邮电大学硕士毕业论文
六.摘要Abstract(介绍作者在做什么 / 知道作者要研究什么)
1.研究背景 / 作者做这个研究的原因
2.作者要解决的问题
当前的异常检测方法通常采用机器学习的方法,从单个时间点而非事件的角度进行异常检测,这类方法既没有有效地利用异常区间的标签,也没有关注异常点之间的差异性。因此,异常检测的性能不够精确,在实际应用中的效果有限。
3.作者解决这个问题的方法
提出了基于多阶段机器学习的连续区间异常检测模型 ALSR:它使用了一个标签筛选模型和一个再学习模型,标签筛选模型利用异常区间的连续性从训练集中移除一些不需要的数据。再学习模型利用随机森林算法对被检出的真/假异常进行重新分类,有效地减少了异常误报的数量。利用滑动窗口提取的多个特征组成的特征集被证明能很好地描述KPI时间序列的特征
4.作者模型的效果
在包含25项KPI数据的数据集上进行了综合实验,获得了0.965的F-score,优于现有的异常检测方案
5.结论Conclusion
- 基于多阶段机器学习的KPI异常检测模型,从算法层面直接考虑连续性异常区间的特点,提出的标签筛选算法与传统的单点异常检测或者变点异常检测不同,充分利用了异常区间内部具有明显异常特征的异常点。
- 为了有效降低异常误报的频率,提出了再学习算法,从更细的粒度分析了被检出异常之间的差异性,在一定程度上修正了正常/异常二分类器的检测误差
七.引言Introduction
1.研究方向的背景 / 作者为什么要研究这个课题
有监督学习和无监督学习是AIOps中通常用的两种方法,无监督学习存在的问题是KPI的正常模式很难定义,例如单类SVM、生成模型等,可以在一定程度上模拟正常数据,但是模拟的正常数据和真实的正常数据之间的差异是不容忽视的。有监督学习的问题是很大程度上取决于标签的准确性。现有的基于监督机器学习的异常检测方法使用单独的时间点进行训练和检测,既不能有效地利用连续异常区间形式的异常标签,也没有分辨区间内部异常点之间的差异。使用未处理的、基于单点的异常训练和检测方案会降低标注数据的有效性。此外,忽略异常点之间的差异性也限制了异常检测方案的泛化性能。
2.研究现状
3.作者要解决的问题是什么
在通常的异常检测场景中,异常时以事件、即连续异常区间的形式出现的。现有的异常检测方案主要使用两种方式进行异常检测:
- 简单地使用单个时间点作为训练和检测的基本单位
- 对异常区间进行变点检测,即关注异常区间的起始点和结束点,异常区间内部的点被完全忽略。
两种方案都没有充分利用存在于连续性异常区间内部的异常点。
4.作者为什么要解决这个问题(作者研究这个问题的原因)
5.作者提出的模型
6.作者的模型是怎么解决问题的(作者的模型在做什么事情)
作者提出的多阶段KPI异常检测模型是使用标签筛选之后的数据进行训练,既对区间内部的异常点进行了差异化处理,同时又兼顾了异常区间内部点的有效利用。
7.作者的创新点
提出一种有监督的学习方法:基于多阶段机器学习的KPI异常检测模型。
- 提出标签筛选算法:利用异常区间内部不同异常点之间的差异性来过滤训练数据,它在算法层面考虑了连续异常区间的特点,并且更加适用于面向区间的异常检测场景
- 使用轻量级的再学习方案,分析被检出异常之间的差异性。它对被检出的异常误报和真实异常进行重新分类,从而在不降低召回率的基础上尽量提升精确率
- 使用统计特征、时间序列模型等方案进行特征提取。精心选择的12项特征能够被应用于拥有不同变化模式的主流KPI类型,同时,中等量级的特征集合能够避免过度的特征冗余。
八.相关概念介绍
KPI时间序列数据可以从页面访问流量、在线人数、点击量等不同指标中获得,三种典型的KPI数据:强周期性KPI、稳定型KPI、波动型KPI,本文的KPI数据不考虑概念漂移,在典型的KPI异常检测场景,KPI异常数据往往以连续区间的形式存在,即异常一旦出现,就会持续一段时间,而不是仅仅存在于单独的时间点,同时,在实际的异常报警中,运维人员更关注每一个异常事件(连续异常区间)的检出,而非每一个异常点的检出。因此,连续区间KPI异常的检出有别于单点异常的检出。算法可以不必精确地确定每一个发生异常的时间点,但是应当在事件的规模上进行准确度更高的异常检测。
单KPI指标数据的异常检测:
常见的机器学习算法有随机森林、深度神经网络、支持向量机等。
基于时间序列预测的算法:常见的有ARIMA模型,机器学习算法有循环神经网络、LSTM等
机器学习在KPI异常检测的应用:
1.监督学习模型:在有标签的场景中,异常检测可以概况为正常/异常的二分类问题,有两种方法
(1) 基于时间序列预测值和阈值结合进行判断
(2) 通过分类器的算法模型:支持向量机SVM,全连接的多层感知机 DNN
2.无监督学习模型
(1) 生成模型:GAN、变分自编码器 VAE、隐马尔可夫模型 HMM
(2) 单类分类器:单类支持向量机 OCSVM”
九.作者提出的模型
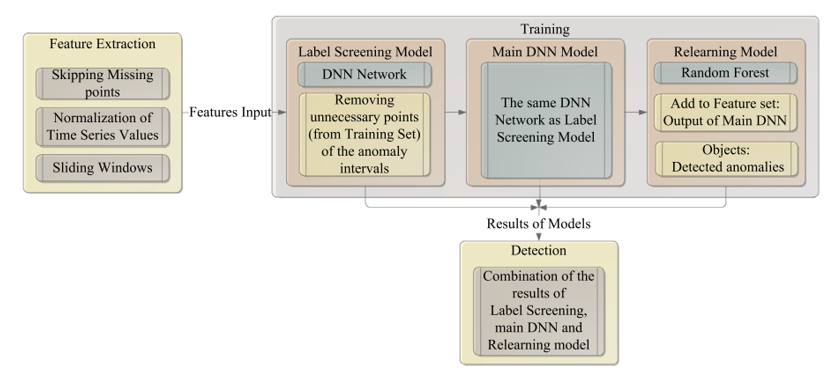
- 基于多阶段机器学习的KPI异常检测模型由特征提取、标签筛选模型、基础DNN模型、再学习模型四个部分组成。
- 为了在连续异常区间中自适应地识别和移除冗余的异常点,提出了基于DNN网络的标签筛选模型,这样充分考虑了异常点之间的差异,尽可能多地利用了具有更高重要性的异常点
- 被检测器分类为异常的点会存在一些误报,所以提出了对被检出异常进行进一步重新分类的再学习模型。
- 标签筛选模型主要针对连续异常区间的特点,将异常区间中少部分不能展现出异常特征的点移除,使得后续模型对于区间内的异常特征有更准确的识别。
- 基础DNN模型则使用基于深度神经网络设计的全连接结构,负责进行正常/异常点的分类工作。
- 最后的再学习模型则是在小范围内对基础DNN模型检出的异常点做进一步的筛查,以便去除可能存在的少量假正例
1.特征提取
使用滑动窗口提取特征,模型使用了12项特征
- 值:标准化的原始KPI值
- 统计特征:均值、方差、极差、四分位数、差分等(原始值和统计特征用于分析KPI数据的短期特征)
- 时间序列预测特征:指数加权移动平均 EWMA预测、AR预测等(时间序列预测结果用于在一定程度上衡量数据的异常可能性)
- 小波分析特征:Db2小波分解(小波分解用于分析KPI数据在频率域上的特征)
2.标签筛选方案设计
使用滑动窗口提取特征产生的训练集被用于标签筛选模型,在标签筛选模型训练之后,被判断为冗余的异常点将会从原始的训练集中被移除,标签筛选模型的分类结果会被保留。
(1) 冗余的异常点:异常区间开始的T个时间戳之外的假负例的点,即异常区间中少部分不能展现出异常特征的点。
(2) 标签筛选模型:使用具有全连接结构的DNN网络,标签筛选模型的分类结果包含四类,真正例、假正例、真负例、假负例
- 真正例 True Positive:对于一段标记的连续异常区间,如果异常检测算法在该连续异常区间开始后的T个时间戳之内检测到了该连续异常区间,则认为此异常检测算法成功地检测到了整段连续异常区间,因此该异常区间内的每一个异常点都记作面向区间的真正例。
- 假负例 False Negative:对于一段标记的连续异常区间,如果异常检测算法在该连续异常区间开始后的T个时间戳之外检测到了该连续异常区间,则该异常区间内的每一个异常点都记作面向区间的假负例。
- 假正例 False Positive:对于一个没有标记异常的时间点,如果异常检测算法检测出了异常,则记作假正例。
- 真负例 True Negative:对于一个没有标记异常的时间点,如果异常检测算法没有检测出了异常,则记作真负例)。
3.基础DNN模型
标签筛选模型筛选过的训练集被用于基础DNN模型的训练,基础DNN模型的输出是正常和异常的分类概率
4.再学习方案设计
将基础DNN模型输出的分类概率加入到标签筛选模型筛选过的训练集中,按照一定比例和数量随机从基础DNN模型输出的真正例、假正例、真负例中采样,组成再学习模型的训练集,进行再学习模型的训练,再学习模型使用随机森林算法。
*注: 标签筛选模型和基础DNN模型的目的是进行正常/异常点的分类,再学习的对象是基础DNN模型检测出的异常点,这些异常点存在误报,去除可能存在的假正例,再学习模型是一个假正例/真正例的分类器。
5.连续区间异常检测评价指标
精确率、召回率、F-score,根据精确率和召回率绘制的PR曲线
十.实验experiments(作者是怎么通过实验证明自己的模型解决了问题)
1.数据集
iops.ai官网公开的预赛训练集和决赛训练集,选择了其中的25条KPI曲线,分成三组,12项强周期型KPI数据,6项稳定型数据、7项波动型KPI数据
2.评价指标是什么
F-score和AUCPR值(PR曲线下的面积)作为衡量异常检测的表现效果,AUCPR值越大表示异常检测效果越好,PR曲线越接近右上角,表示同时具有更高的精确率和召回率。
(PR曲线:精确率和召回率曲线)
3.实验的步骤
把支持向量机 SVM、长短期记忆网络LSTM、随机森林RF、Opprentice和多阶段KPI异常检测模型在三组数据集上作对比实验
4.实验结果:图和表是怎么证明作者解决了问题
多阶段KPI异常检测模型ALSR具有更好的稳定性,ALSR在总体数据集上的F-score是0.965,优于其它算法
十一.这篇文章存在哪些缺陷
1.本文主要讨论了三种主流的KPI类型,在实际场景中,还有很多其他变化类型的KPI,对于异常检测算法可以进一步讨论同一个模型对于不同类型的KPI的通用性,以及多种异常检测模型的自适应选择方案,从而应对复杂多变的实际运维场景
2.有监督学习往往准确度高,但是对标签有依赖性,实际应用中很难获取大量标签,无监督学习不需要标签,但是因为缺乏参照,阈值和参数很难确定,实际场景中可能只存在少量标签的异常检测需求,可以考虑把有监督学习和无监督学习算法结合,使用无监督学习降低对标签的依赖性,同时使用少量的标签和用户反馈进行有监督学习。

