



一.KPI的定义
- 运维人员收集各种不同的监控指标数据,最终形成以“时间戳( time stamp)和数值(value) ”键值对为主要形式的数据,称为关键性能指标(Key Performance Indicator)数据,简称KPI数据
- KPI数据绝大部分从本质上来说都是时间序列数据,即按时间发生的先后顺序排列的一组数值序列,通常一组时序数据的时间间隔是以秒、分、天、周、月为单位的恒值。
二.KPI的类型
根据服务类型和数据特征,可以将 KPI 分成两种类型:
- 周期性服务KPI:通常是在互联网业务层面的分钟级的统计指标,例如网页访问量、在线用户数量、网页响应时间等,大多数是季节性的平滑 KPI,用来反映服务的质量和规模
- 非周期性机器KPI:通常反映机器(服务器、路由器、交换机)健康状况的秒级的统计指标,例如服务器每秒处理的 I/O请求数量、内存使用率、CPU使用率等,它们的噪声不服从高斯分布,虽然短时间内剧烈抖动,但是长时间内又有一定的趋势性。因此,这类KPI 的分布十分复杂,较难建模
三.云环境中时序数据的特点
- 顺序性:数据点是根据时间顺序进行排列的,在时间轴上遵循事件发生的先后顺序,因此不能把数据点孤立,应结合数据相互影响关系,分析前后关联
- 随机性:时间序列数据的采集受多种因素影响,其值具有随机性和不确定性,数据中存在噪声
- 高维性:时序数据的高维性在于数据采集的时间点过多,若一个时间点表示一个维度,整体数据量极为庞大
- 季节性:云环境中的时序数据按照某种特定的规则循环出现
四.KPI异常
当 KPI 呈现出异常( 例如突增、 突降、 抖动) 时,往往意味着与其相关的应用发生了一些潜在的故障。比如网络故障、服务器故障、配置错误、缺陷版本上线、网络过载、服务器过载、外部攻击等。
- 对于周期性服务 KPI, KPI 异常指的是 KPI 数据不遵循周期性模式,即 KPI 数值的大小发生了明显变化使得数据整体不再呈现周期性
- 对于非周期性机器 KPI, KPI 异常指的是 KPI 数值的大小、变化等特征发生了明显改变
五.时序数据的异常类型
- 点异常:指在不考虑数据点的时间关系的情况下,某些超出了 KPI 序列正常范围的离群点
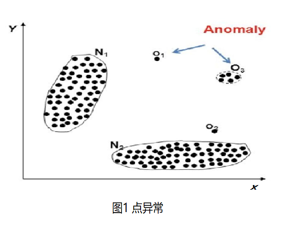
- 上下文异常 :指在某些情况下, 虽然数据点仍在 KPI序列正常范围内,但与邻居点存在很大差异
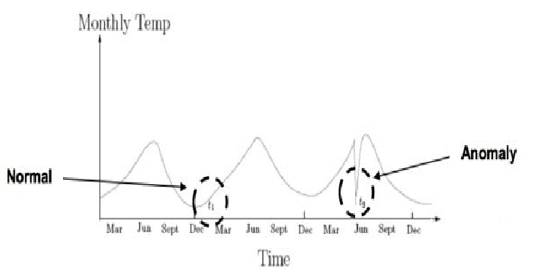
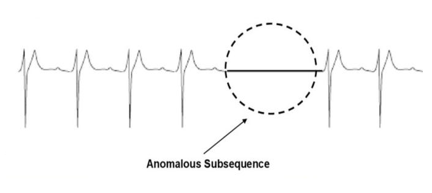
- 集合异常:指某些数据点的集合相对于整个 KPI 序列是异常的。集合异常的各个数据点本身可能不是异常的,但作为集合一起出现会被视为异常
六.云环境中时序数据的常见异常类型
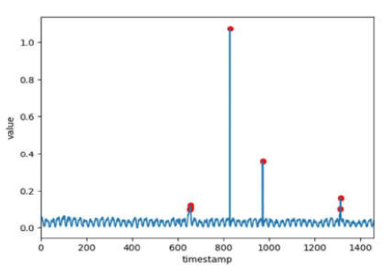
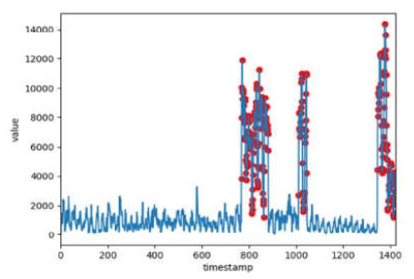
- 离群异常点: 给定一段时间序列,如果在t时刻的观测值与该序列在t时刻的期望值有较大的差异,则称该点为离群异常点。
- 断层异常点:给定一段时间序列,如果在t时刻前后,序列的行为表现出较大的差异,则t时刻对应的点为断层异常点。云环境中的此类异常往往是由于重新开启或关闭了某服务而导致了相应KPI曲线发生断层式的瞬时改变。
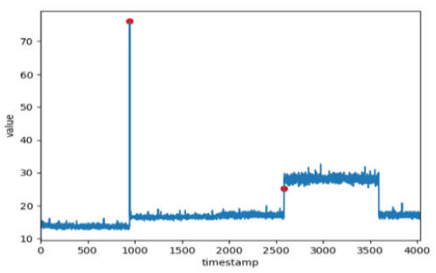
- 异常子序列:给定一段时间序列,如果存在一段子序列,子序列的行为与序列中的大部分表现出较大的差异,则称该段子序列为异常子序列
七.时间序列的异常检测算法
1.基于预测的异常检测算法
- 通过比对预测结果和实际时间序列,并设定阈值,超过阈值则判定为异常
- 主要适用于具有线性趋势和周期波动的KPI序列
- 自回归移动平均模型(ARIMA)
- Holt-Winters模型
- 支持向量回归(SVR)
2.基于机器学习的异常检测算法
- 支持向量机(SVM)
- 孤立森林(iForest):采用构建多个决策树的方式进行异常检测,但只适合检测全局异常点,不适合做局部异常点的检测
- 主成分分析(PCA)
- One-class SVM
- DBSCAN
- 混合高斯模型(GMM)
- 局部异常因子(LOF)
- K近邻算法(KNN)
3.基于深度学习的异常检测算法
- 循环神经网络(RNN)及其变体
- 长短期记忆网络(LSTM)及其变体:可以解决长时依赖问题。具有长期记忆功能
- 自编码器(Autoencoder,AE):它由编码器(encoder)和解码器(decoder)两个部分组成
- 变分自编码器(VAE):可以实现和自编码器类似的作用,不同的是变分自编码器可以学习到隐变量的分布
- 生成对抗网络(GAN)及其变体:生成器试图将输入的噪声转换为逼真的伪样本以欺骗鉴别器,而鉴别器试图区分数据是真实的样本还是来自生成器的伪样本
- 卷积神经网络(CNN):能够很好的提取数据的局部特征
- 加入注意力机制 ( Attention Mechanism )

