



梯度下降法
是一种致力于找到函数极值点的算法
梯度
梯度表明损失函数相对参数的变化率
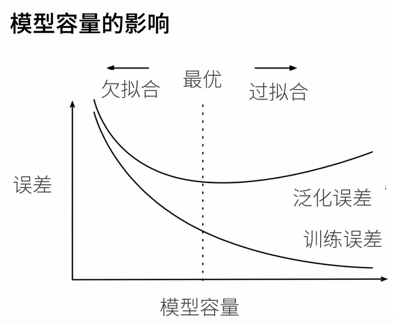
泛化误差
模型在新数据上的误差
降维
1.特征选择
2.PCA 主成分分析
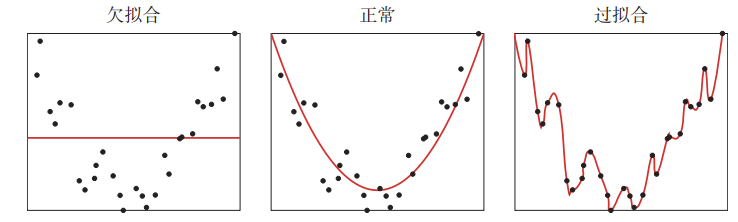
欠拟合
在训练数据上错误率比较高,模型不能很好地拟合数据
过拟合
在训练数据上错误率低,在测试数据上错误率很高
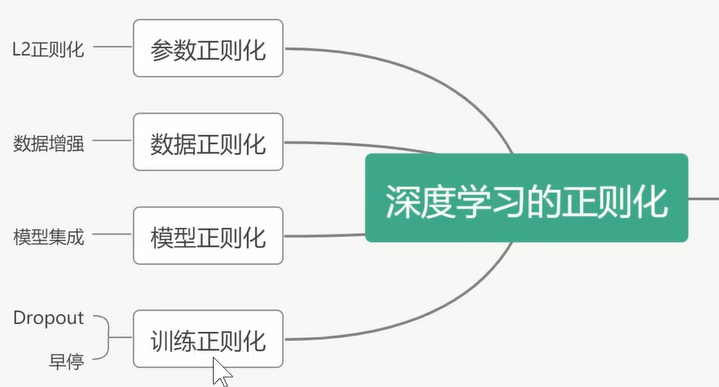
抑制过拟合的方法:正则化
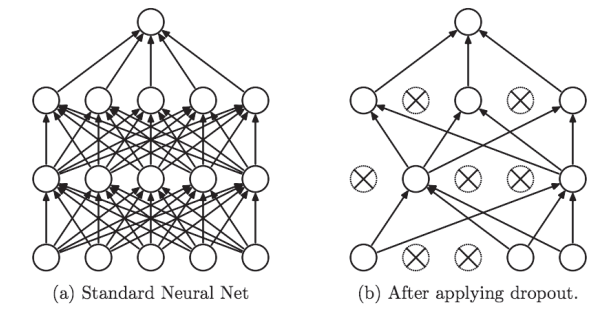
dropout 丢弃法
1.是一种在学习的过程中随机删除神经元的方法
1.丢弃法将一些输出项随机置0来控制模型复杂度
2.常作用在多层感知机的隐藏层输出上
损失函数
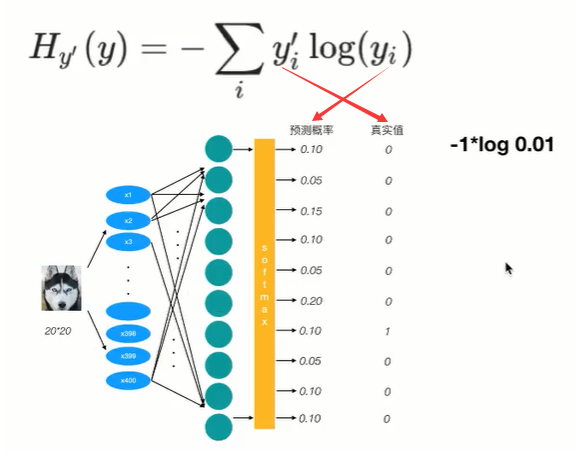
1.交叉熵损失函数
(1) 交叉熵刻画的是实际输出与期望输出的距离,也就是交叉熵的值越小,两个概率分布就越接近
(2) 目标值需要进行one-hot编码,能与概率值一一对应
神经元(感知机)
1.概念
神经元模型是一个包含权重的输入,并且使用激活功能产生输出信号的基础计算单元,包括三个部分:输入、激活、输出
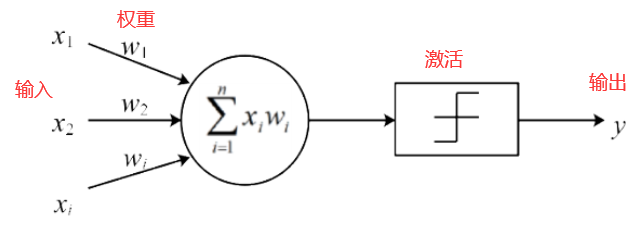
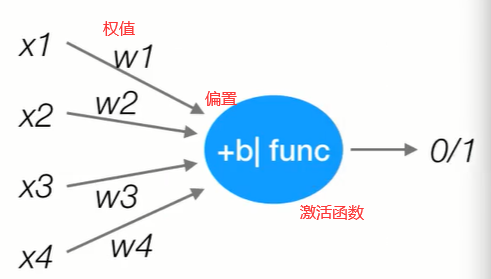
激活部分一般由两模块组成:
第一个模块是对输入部分进行加权求和,并且加入偏置项之后得到的结果进行如公式所示的表征函数f()转换处理
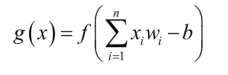
第二个模块是对f()处理后的结果进行激活,常用的激活函数有:sigmoid函数等
激活函数
激活函数是加权输入和神经元输出的简单映射
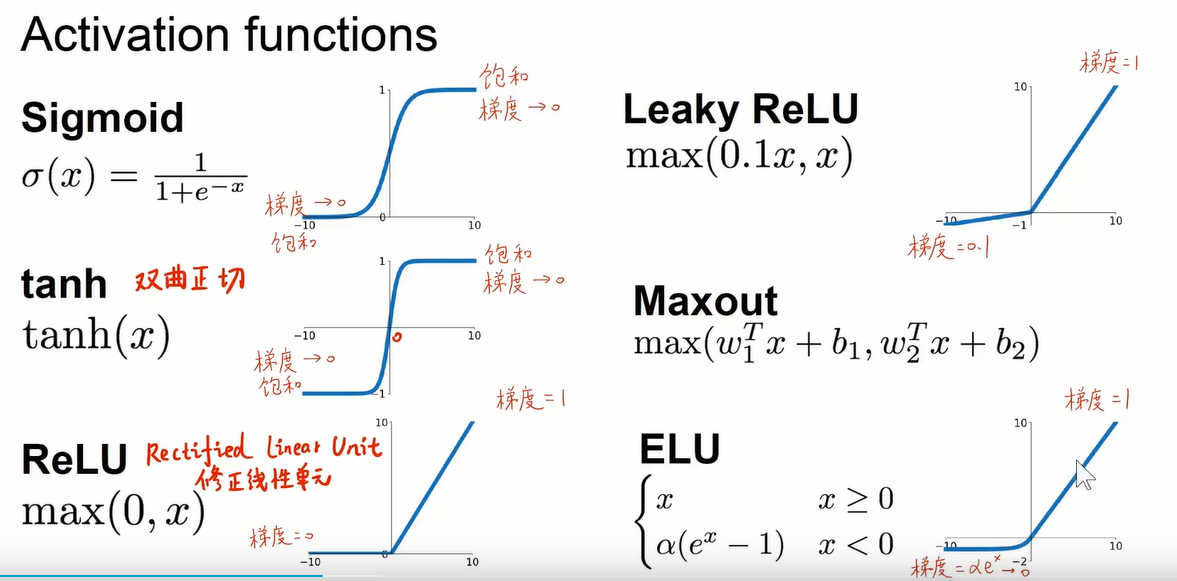

softmax函数
把神经网络的输出转化成概率
全连接
任意一个神经元和前后层的所有神经元相连接
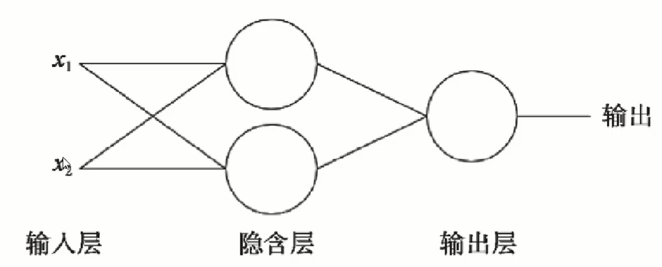
多层感知机(神经网络)
是一种前馈人工神经网络模型,其将输入的多个数据集映射到单一的输出的数据集上,传统的神经网络有输入层、隐藏层、输出层,其中隐藏层的层数根据需要而定
卷积神经网络 CNN
包括输入层,隐藏层(包含:卷积层、激活层、池化层),输出层(全连接层)
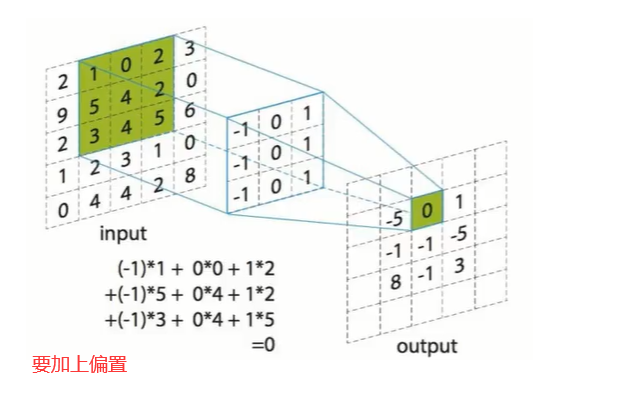
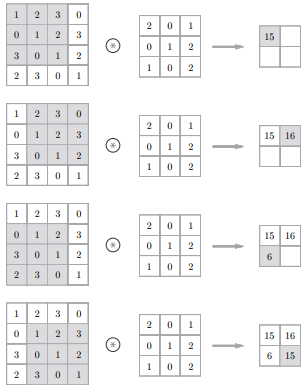
1.卷积层(Convolution)
(1) 卷积层的作用是特征提取
(2) 每层卷积层是由若干个卷积单元(卷积核 Convolution Kernel,又称 滤波器 Filter)组成
(3) 组成卷积核的每个元素都有与之对应的偏置和权重系数
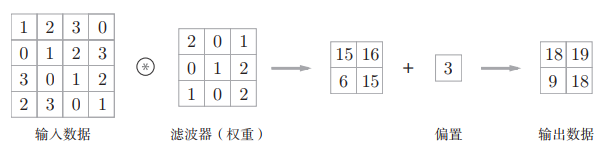
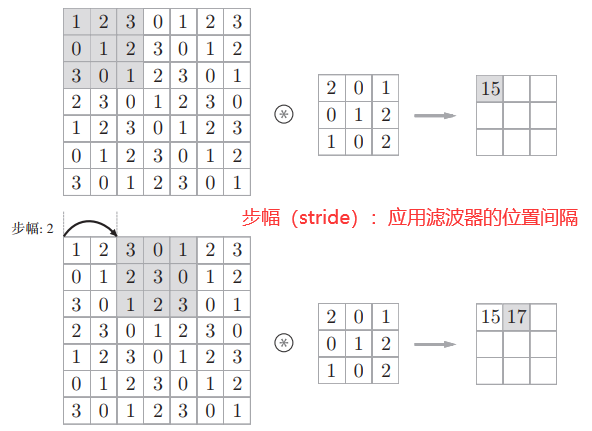
(4) 卷积的过程就是待卷积区域与卷积核点乘并加上偏置后的激活输出
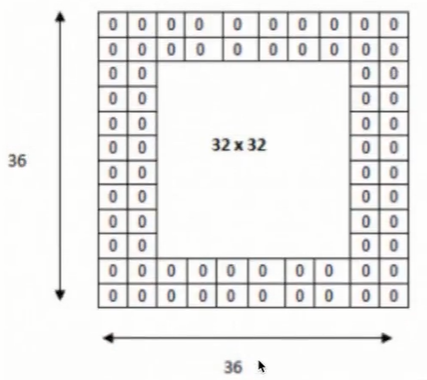
(5) 卷积核的填充(padding)
在进行卷积层的处理之前,有时要向输入数据的周围填入固定的数据(比如0等)
(6) 卷积层的输出也称为特征映射(feature map)
2.池化层(Polling)
(1) 池化层的作用是对由卷积层的输出进行信息过滤和特征提取
(2) 最大池化:是从目标区域中取出最大值
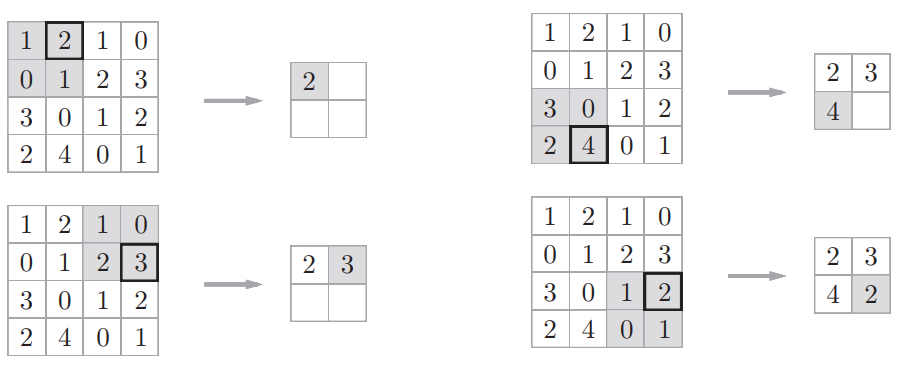
3.全连接层(Full Connection)
起分类器的作用
循环神经网络 RNN
在时间t,模型输出值Yt取决于两个参数:隐藏层到输出层的连接权重Wy和当期状态值Ht,
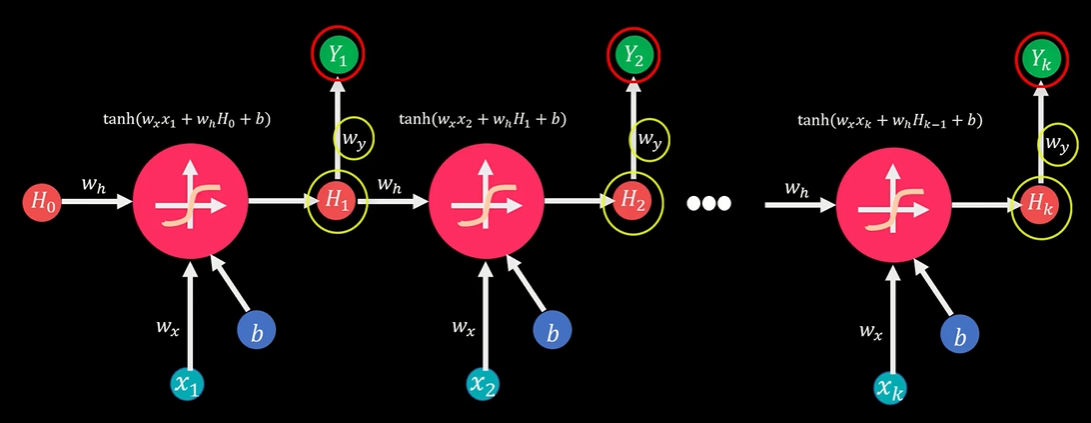
输入值Xt和上期的状态值Ht-1通过相应的连接权重Wh和Wx,加权相加,再通过激活函数TanH,生成当期的状态值Ht,而Ht在下期计算中又会作为状态输入值与Xt+1一起参与到Ht+1的计算
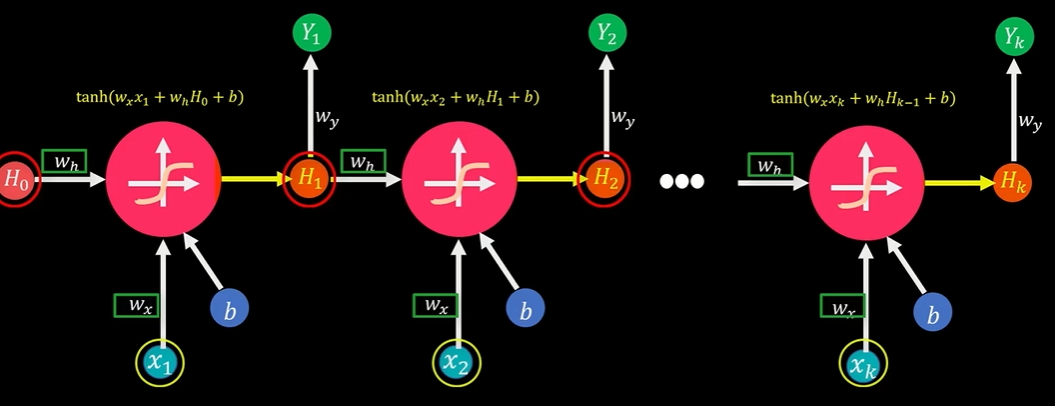
循环神经网络的优化问题
1.梯度消失
2.梯度爆炸
3.长时依赖
LSTM 长短时记忆网络
主要是解决循环神经网络RNN存在的梯度消失和梯度爆炸的问题,LSTM的结构和标准RNN类似,区别是LSTM把隐藏层的每个普通节点换成了一个记忆细胞,具备选择性记忆的功能,可以选择记忆重要信息,过滤掉噪声信息,减轻记忆负担
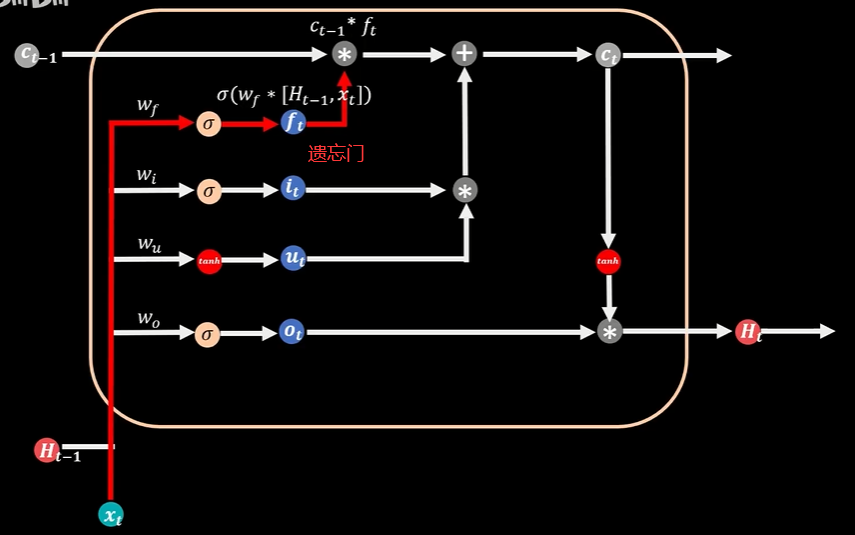
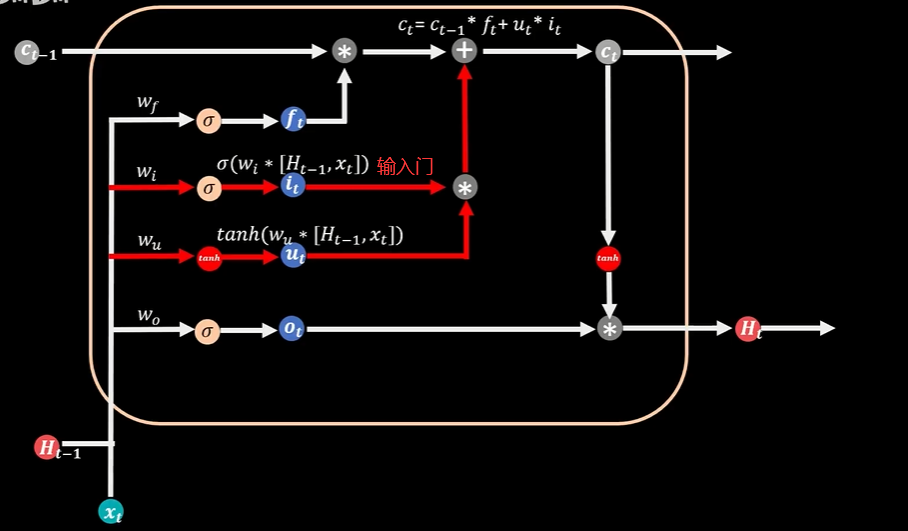
3个Sigmoid函数,两个Tanh函数,Sigmoid函数可以返回0到1区间的值,TanH可以返回-1到1区间的值,3个Sigmoid函数分别管理着三扇门:遗忘门、输入门、输出门
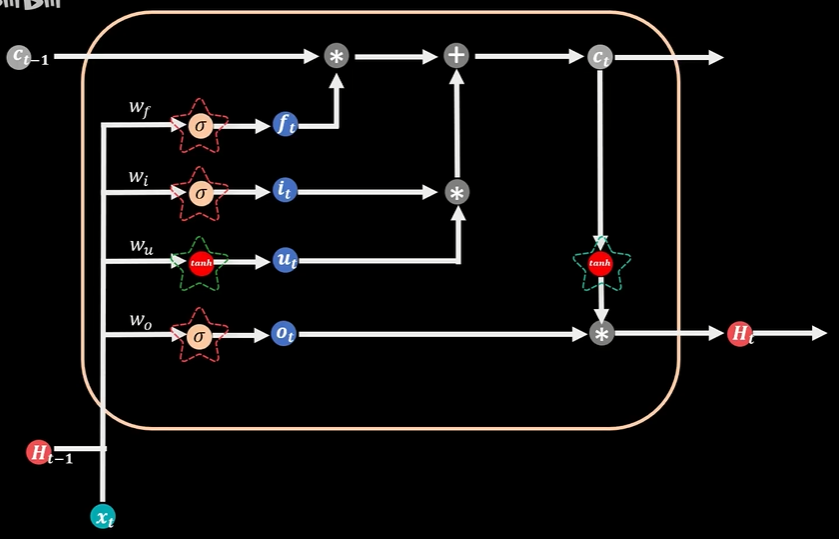
本期记忆状态值Ct由上期状态记忆值Ct-1通过遗忘门过滤到本期的部分加上本期新增的部分,上期过滤的部分是依靠遗忘门,当遗忘门的值为0时意味着上期记忆完全遗忘,当遗忘门的值为1时,上期记忆全部保留
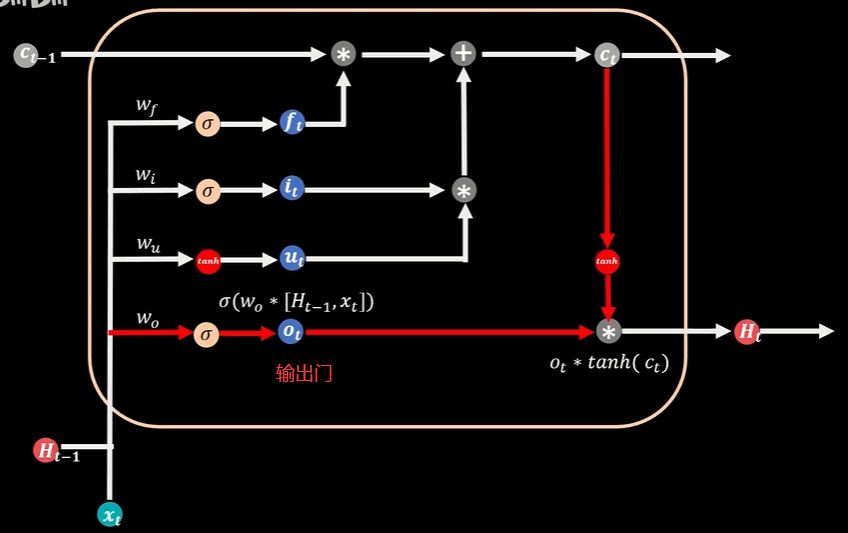
输出门的Sigmoid函数和当期记忆值Ct的TanH值相乘,得到本期的输出值Ht,Ct和Ht会循环流入到t+1时刻参与到下期的计算
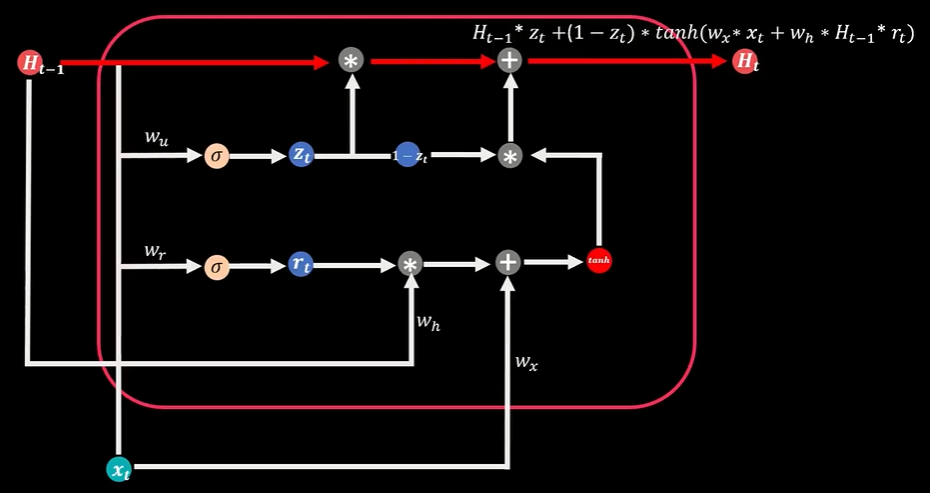
门控循环单元GRU
两个Sigmoid函数代表两扇门:更新门、重置门
计算当期状态值Ht时,同时考虑历史信息部分和新增信息部分,更新门确定着上期状态能进入到当期的比例,当它与上期状态值Ht-1相乘,就得到了新状态中历史信息的部分
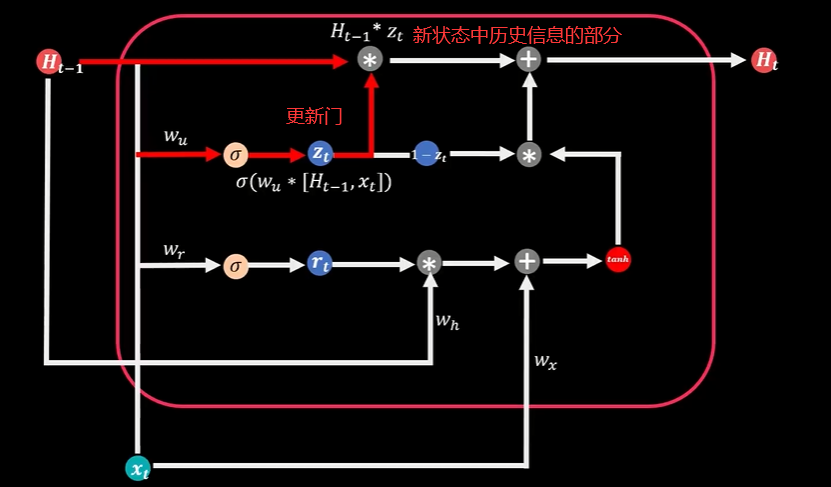
重置门决定了上期信息的遗忘比例,它与上期状态Ht-1相乘,并且和当期输入信息部分Xt相加,再通过TanH函数转化得到当期信息数据,当期信息数据和对应比例(1-Zt)相乘,得到新状态中新增信息的部分
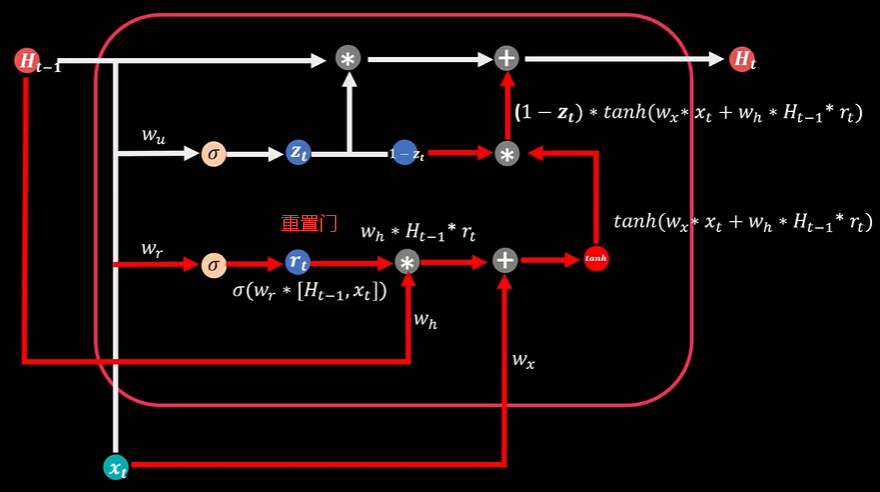
历史信息部分和新增信息部分相加得到最终当期状态值
注意力机制 Attention Mechanism
自编码器 AE
变分自编码器 VAE
seq2seq 编码器和解码器
生成对抗网络 GAN
生成器(G)试图将输入的噪声转换为假样本,试图欺骗鉴别器(D),而鉴别器(D)试图区分数据是真实的样本还是来自生成器(G)的假样本,在训练迭代过程中,生成器和鉴别器持续地进化和对抗,直到达到平衡状态,鉴别器无法识别出生成器的假样本,训练结束
深度卷积生成对抗网络 DCGAN
DBSCAN算法
DBSCAN算法是经典的基于密度的聚类算法,它依靠数据点间定义的密度度量来聚类。它通过指定数据聚类最小点数MinPts,和聚类距离半径ε自动依据数据点的密度聚类。相对于我们熟悉的K-means算法,不需要指定聚类的个数。聚类是一种无监督学习,它在样本没有标记的情况可以把数据分成不同的组,聚类算法分组的依据是数据间的距离度量值。

