



一.Numpy的作用
Numpy用于快速处理任意维度的数组,支持常见的数组和矩阵操作,Numpy提供了一个N维数组类型ndarray,使用ndarry对象处理多维数组
二.导包
import numpy as np
三.Numpy数据类型
1.布尔型:bool
2.整型:int32,int64,int128
3.浮点数:float32,float64,float,longfloat
4.字符串:string,unicode
5.对象:object
6.时间:datetime64,timedelta64
四.创建数组 / ndarry
ndarray是N维数组对象
1.创建一维数组
(1)
np.array([列表])
x = np.array([1,2,3,4,5,6])
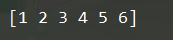
(2) 创建数组的时候指定数据类型
np.array([列表], dtype=np.数据类型)
x = np.array([1,2,3,4,5,6], dtype=np.float32)

2.创建二维数组
嵌套列表
(1)
np.array([[列表1],[列表2],...])
X = np.array([[1,2,3,4],[5,6,7,8]])

(2) 创建数组的时候指定数据类型
np.array([[列表1],[列表2],...], dtype=np.数据类型)
x = np.array([[1,2,3,4],[5,6,7,8]], dtype=np.float32)

- np.array(),是深拷贝
- 深拷贝:只是把值赋值过去,不把两者关联,一个数组的值改变,不会引起另一个数组的值改变
- 在创建数组 / ndarray的时候,如果没有特别指定,浮点数默认是float64,整数默认是int64
3.创建数组的函数
(1)创建全是1的数组:ones
np.ones(shape[, dtype=None, order='C])
x = np.ones(6)
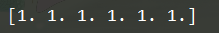
x = np.ones((2,3))
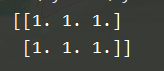
x = np.ones((2,3), dtype=np.int32)
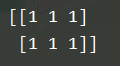
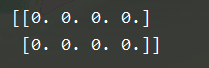
(2) 创建全是0的数组:zeros
np.zeros(shape[, dtype=None, order='C])
x = np.zeros(6)

x = np.zeros((2,4))
(3) 创建数字序列:arange
区间是左闭右开 [start,stop),不包括stop
arange(start, stop, step, dtype)
x = np.arange(8)

x = np.arange(2,10,2)

(4) np.copy() 深拷贝
a = np.array([1,2,3,4])
b = a[2:4]
b[0] = 6 # b的值改变,会改变数组a的值

a = np.array([1,2,3,4])
b = a[2:4].copy()
b[0] = 6 # b的值改变,不会改变数组a的值
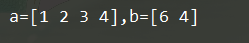
(5) np.asarray(a, dtype=np.数据类型) 浅拷贝
(6) 生成等间隔序列:np.linspace(start, stop, num, endpoint, retstep, dtype)
- start:序列的起始值
- stop:序列的终止值
- num:要生成的等间隔样例数量,默认为50
- endpoint:如果为true,该值包含于序列中,endpoint序列中是否包含stop值,默认为ture
- retstep:如果为true,返回样例,以及连续数字之间的步长
- dtype:输出ndarray的数据类型
a = np.linspace(0,60,10)

(7)创建和数组a形状相同的全是1的数组:zeros_like
np.zeros_like(a, dtype=None)
(8) 创建和数组a形状相同的全是0的数组:empty_like
empty_like(a, dtype=None)
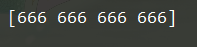
(9) 创建指定值的数组:full
np.full(shape, value, dtype=None, order='C)
x = np.full(4,666)
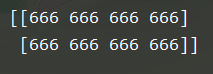
x = np.full((2,4), 666)
(10) 创建和数组a形状相同的数组:full_like
np.full_like(a, value, dtype=None)
五.ndarray的属性
1.数组的形状:ndarray.shape,返回值是一个元组
x = np.array([1,2,3])

x = np.array([[1,2,3],[4,5,6]])

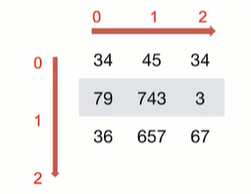
x = np.array([[[1,2,3],[4,5,6]],[[7,8,9],[10,11,12]]])

2.数组中元素的数据类型:ndarray.dtype
3.数组中的元素数量:ndarray.size
4.一个数组元素的长度(字节):ndarray.itemsize
5.数组的维度的数目:ndarray.ndim
6.数组转置:ndarry.T
7.修改数组的类型:
(1) ndarry.astype(np.数据类型)
会返回新的数组,不是引用机制,即新的数组值的改变不会引起之前的数组值改变
a = np.array([1,2,3,4])
b = a.astype(np.float32)
b[0] = 0.5

(2) ndarry.tostring()
8.数组a去重:ndarry.unique(a)
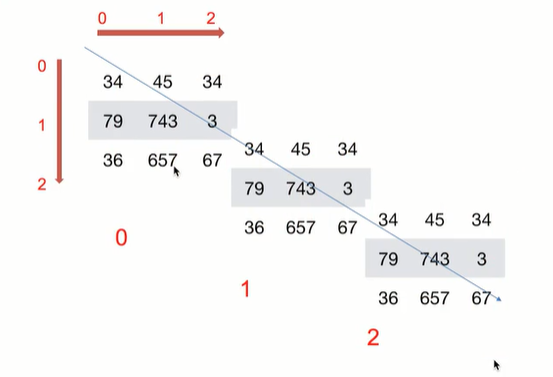
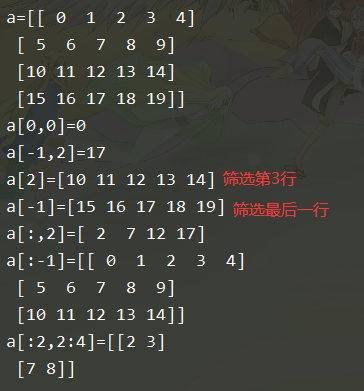
六.切片 / 索引
切片在内存中是引用机制,切片的修改会修改原来的数组
1.基础索引
行索引从0开始,第一行的索引号是0
列索引从0开始,第一列的索引号是0
(1) 一维数组索引

(2) 二维数组索引
- a[行索引, 列索引]
- a[start : end : step, start : end : step]:每一个维度都支持切片,左闭右开的区间[start,end),不包括end,start和end都是索引号,索引从0开始
- a[索引]: 单个索引是索引一整行
- a[:, 列索引]: 省略行索引,表示从第一行到最后一行,即 整列
- 负索引:倒数第几行 / 倒数第几列
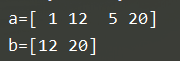
2.布尔索引
b = a>10

b = a[a>10]
a[a>10] = a[a>10] + 5

b = a[:, 3] > 7 # 筛选出第3列的值大于5的行
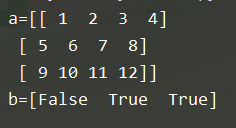
b = a[a[:, 3] > 7]

b = (a%2==0)| (a>7)

condition = (a%2==0)| (a>7)
b = a[condition]
七.np.where(a)
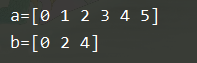
where的返回值是一个元组,返回的是索引位置
b = np.where(a>10)

八.数组和数的运算
b = a + 1

b = a / 2

b = a * 3

九.数组和数组的运算
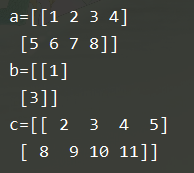
1.数组和数组相加
c = a + b
2.数组合并
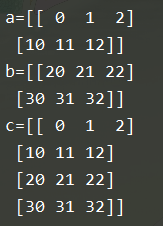
(1) np.concatenate((a,b), axis=0):添加行
c = np.concatenate((a,b))
(2) np.concatenate((a,b), axis=1):添加列
c = np.concatenate((a,b), axis=1)
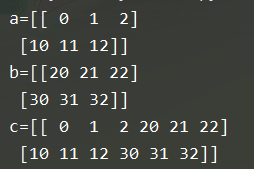
(3) np.vstack((a,b)):添加行
c = np.vstack((a,b))
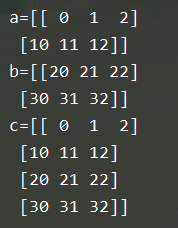
(4) np.hstack((a,b)):添加列
c = np.hstack((a,b))
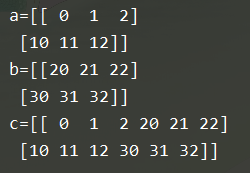
(5) np.row_stack((a,b)):添加行
(6) np.column_stack((a,b)):添加列
2.数组分割
np.split(ary, indices_or_sections, axis=0)
b = np.split(a, 3)
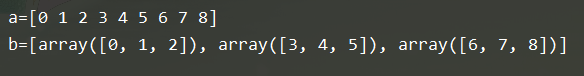
b = np.split(a, [3,5,6,10])

十.矩阵运算
1.矩阵和数组的区别
矩阵必须是二维的,数组可以是多维的
2.存储矩阵matrix的方式
(1) ndarray二维数组: np.arrary()
a = np.array([[80,86],
[82,80],
[85,78],
[90,90],
[86,82],
[82, 90],
[78,80],
[92,94]])
(2) matrix数据结构: np.mat(a)
a = np.mat([[80,86],
[82,80],
[85,78],
[90,90],
[86,82],
[82, 90],
[78,80],
[92,94]])
3.矩阵乘法
(1) 用ndarray二维数组存储的矩阵:通过np.array()创建的矩阵
- np.matmul(a,b)
- np.dot(a,b)
(2) 用matrix数据结构存储的矩阵: 通过np.mat()创建的矩阵
a * b
十一.使用random生成随机数的数组
1.np.random.uniform(low=, high=, size=)
- 在[1ow,high)之间随机采样生成均匀分布的数字
- low:采样下界,float类型,默认值是0
- high:采样上届,float类型,默认值是1
- size:输出样本数目,为int或者元组类型
- 返回值:ndarray类型,形状和参数size一样
a = np.random.uniform(1,10,10)

a = np.random.uniform(1,10,(3,4))

2.np.random.normal(loc=, scale=, size=)
- 按照平均值loc和方差scale生成高斯分布的数字
- loc是float类型
- scale是float类型
a = np.random.normal(1,10,10)

a = np.random.normal(1,10,(3,4))

3.np.random.seed(seed)
设定随机种子,这样每次生成的随机数会相同
4.np.random.rand(d0, d1,…. dn)
返回在[0,1)之间均匀分布的数
a = np. random.rand(5)

a = np. random.rand(3, 4)

a = np. random.rand(2, 3, 4)
5.np.random.randn(d0, d1,…. dn)
返回数据具有标准正态分布(均值0, 方差1)
a = np. random.randn()

a = np. random.randn(3)

a = np. random.randn(3, 2)
a = np. random.randn(3, 2, 4)
6.np.random.randint(low, high, size, dtype)
生成随机整数,包含1ow, 不包含high
a = np. random.randint(3)
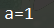
a = np. random.randint(1, 10)
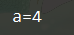
a = np. random.randint(10, 30, size=(5, ))

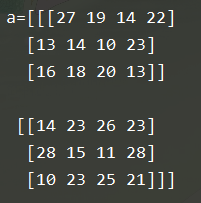
a = np. random.randint(10, 30, size=(2,3,4))
7.np.random.random(size)
生成[0.0,1.0)的随机数
a = np.random.random (5)

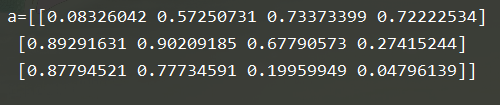
a = np.random.random(size=(3,4))
a = np.random.random(size=(2,3,4))
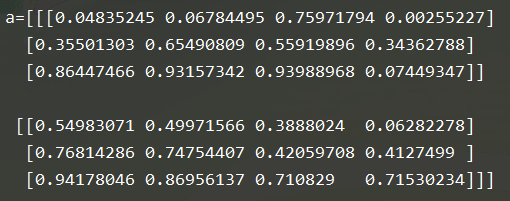
8.np.random.choice(a,size, replace, p)
a是一维数组,从它里面生成随机结果
a = np.random.choice(5, 3) #这时候,a是数字,则从range(5) 中生成,size为3
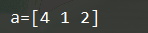
a = np.random.choice(5, (2,3))
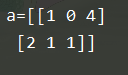
a = np.random.choice([1,2,3,4,5], 3) #这时候,a是数组,从里面随机取出数字
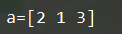
a = np.random.choice([1,2,3,4,5], (2,3))

9.np.random.shuffle(x)
把一个数组x进行随机排列
a = np.arange(10)
np.random.shuffle(a)

10.np.random.permutation(x)
把一个数组x进行随机排列,或者数字的全排列
a = np.random.permutation(10) #生成range(10)的随机排列

十二.增加数组的维度
1.ndarray.reshape(行,列) 或者 np.reshape(a,(行,列))
从一维增加到二维,reshape()不会修改原来数组的值,而是返回一个新的数组
x = np.arange(6)
x1 = x.reshape(2,3) # 把一维数组变成2行3列的二维数组
等价于 x = np.arange(6).reshape(2,3)

a = np.array([1,2,3,4,5,6])
b = np.reshape(a, (2,3))

2.np.newaxis关键字
使用索引的语法给数组添加维度
(1) 给一维向量添加一个行维度
ndarray[np.newaxis, :]
a = np.array([0,1,2,3,4])
b = a[np.newaxis, :]
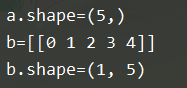
(2) 给一维向量添加一个列维度
ndarray[:, np.newaxis]
a = np.array([0,1,2,3,4])
b = a[:, np.newaxis]

3.np.expand_dims(arr, axis)
axis = 0:代表列
axis = 1:代表行
(1) 给一维向量添加一个行维度
np.expand_dims(ndarray, axis=0)
a = np.array([0,1,2,3,4])
print(f"a.shape={a.shape}")
b = np.expand_dims(a, axis=0)
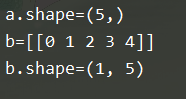
(2) 给一维向量添加一个列维度
np.expand_dims(ndarray, axis=1)
a = np.array([0,1,2,3,4])
b = np.expand_dims(a, axis=1)

十三.数学统计函数
1.所有元素的和:np.sum
b = np.sum(a)

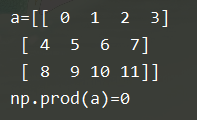
2.所有元素的乘积:np.prod
b = np.prod(a)
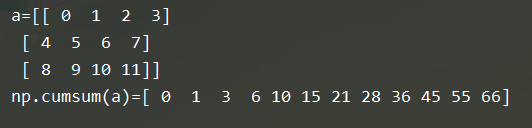
3.元素的累积加和:np.cumsum
b = np.cumsum(a)
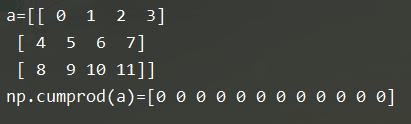
4.元素的累积乘积:np.cumprod
b = np.cumprod(a)
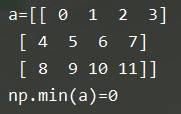
5.最小值:np.min
b = np.min(a)
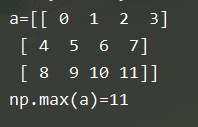
6.最大值:np.max
b = np.max(a)
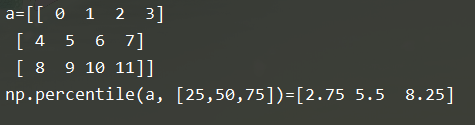
7.0-100百分位数:np.percentile
b = np.percentile(a, [25,50,75])
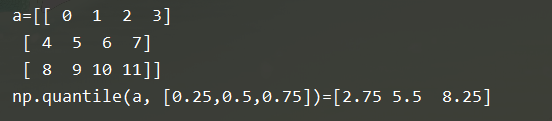
8.0-1分位数:np.quantile
b = np.quantile(a, [0.25,0.5,0.75])
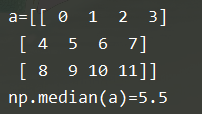
9.中位数:np.median
b = np.median(a)
10.平均值:np.mean
b = np.mean(a)

11.加权平均:np.average,参数可以指定weights
12.标准差:np.std
13.方差:np.var
十四.排序
1.np.sort(a)
2.np.argsort(a)
argsort返回从小到大的排列在数组中的索引位置
十五.通用判断函数
(1) np.all()
只要有一个False就返回False,只有全是True才返回True
(2) np.any()
只要有一个True就返回True,只有全是False才返回False

