



一.导包
import pandas as pd
二.Pandas的基本数据结构
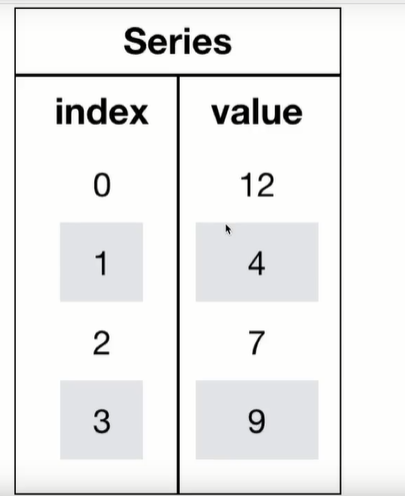
1.Series
带索引的一维数组,和Numpy的一维数组类似,Series要求所有类型相同
一维Series可以用一维列表初始化,默认情况下,Series的下标是数字,类型是统一的
DataFrame是Series的容器
2.DataFrame
DataFrame是既有行索引,又有列索引的二维数组,DataFrame是Series的容器,DataFrame要求每一列数据的格式相同
df = pd.DateFrame(数据, index=, columns=) # index是行索引,columns是列索引,索引值从0开始
import numpy as np
import pandas as pd
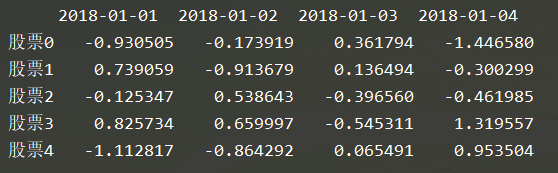
stock_change = np.random.normal(0, 1, (5, 4))
pd.DataFrame(stock_change)
stock = ["股票{}".format(i) for i in range(5)]
date = pd.date_range(start="20180101", periods=4, freq="B")
df = pd.DataFrame(stock_change, index=stock, columns=date)
print(df)
三.DataFrame的属性
1.查看类型
df.shape
2.查看行索引列表
df.index
3.查看列索引列表
df.columns
4.查看数据值
df.values

5.T
6.查看最前面几行的数据(默认是5)
df.head()
7.查看最后几行的数据(默认是5)
df.tail(num)
四.DataFrame索引的设置
1.修改行列索引值
df.index=
不能修改单个的索引值
df.index[3]="test" # 错误的
2.重设索引
data.reset_index(drop=False)
drop:默认为False,不删除原来索引,如果为True,删除原来的索引值
3.以某列值设置为新的索引
set_index(keys, drop=True)
keys: 列索引名或者列索引名称的列表
drop: 默认是True,当做新的索引,删除原来的列
五.DataFrame的数据操作
1.直接使用行列索引(先列后行)
df['列索引名', '行索引名']
2.按名字索引
df.loc['行索引名', '列索引名']
3.按数字索引
df.iloc()
df.iloc[开始索引, 结束索引] # 是左闭右开的区间[,),不包括结束索引的数据
4.赋值操作
data["列名"] = 值
data.列名 = 值
data.iloc[start, end] = 值 # [start,end)
六.DataFrame的运算
1.逻辑运算
data["p_change"] > 2 # 返回一组带索引的布尔值
data[(data["p_change"] > 2) && (data["open"] > 15)] # 筛选 p_change > 2 并且 open > 15 的数据
data.query(条件)
七.Series的创建
series结构只有行索引
1.通过已有数据创建
(1) 指定内容,默认索引
pd.Series(np.arange(10))
(2) 指定索引
pd.Series([6,7,4,5,1], index=[1,2,3,4,5])
2.通过字典数据创建
pd.Series({'red':100, 'blue':200})
八.排序
1.对内容排序
(1) DataFrame
df.sort_values(key=, ascending=) # 默认升序
降序:ascending = False
升序:ascending = True
单个键:by = “”
多个键:by = [“”, “”]
(2) Series
series.sort_values(ascending=) # series排序时,只有一列,不需要参数
2.对索引排序
(1) DataFrame
df.sort_index()
(2) Series
series.sort_index()
九.文件的读取和存储
1.CSV
(1) 读取数据
pd.read_csv("路径")
(2) 存储数据
dataFrame.to_csv("路径", columns=["列名"])
2.JSON
pd.read_json("路径")
十.处理缺失值
1.缺失值是np.nan
(1) 判断数据中是否有缺失值
pd.isnull(df) # 返回一个布尔值对象
pd.notnull(df)
(2) 删除有缺失值的数据 或者 替换/填充缺失值
df.dropna(inplace=False) # 删除含有缺失值的数据
df.fillna(value, inplace=False) # 替换/填充
inplace = True:覆盖之前的数据
axis = 0:选择行或者列
how = “all”:删除全为空值的行或者列
2.缺失值不是np.nan
(1) 把缺失值替换成np.nan
df.replace(to_replace="?", value=np.nan)
十一.数据离散化
1.对数据进行分组
(1) 自动分组
sr = pd.qcut(data, bins)
(2) 自定义分组
sr = pd.cut(data, bins)
2.统计每组的个数
series.value_counts()
3.将分组好的结果转换成one-hot编码
pd.get_dummies(sr, prefix="分组名字")
十二.合并
1.按行或列合并
pd.concat((data1,data2), axis=)
axis=0:列
axis=1:行
2.按索引合并
pd.merge(left, right, how="inner", on=[索引])

