



一. 安装python解释器
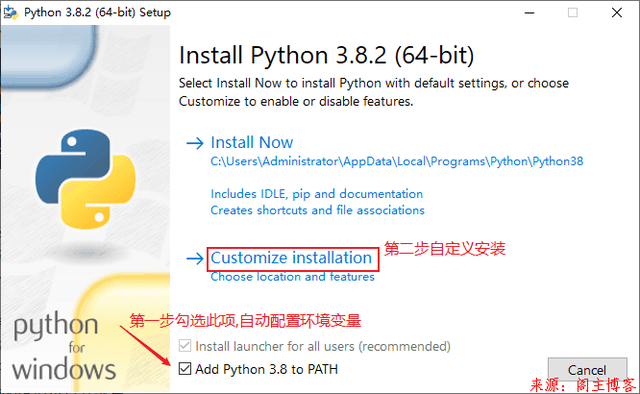
二. 安装PyCharm
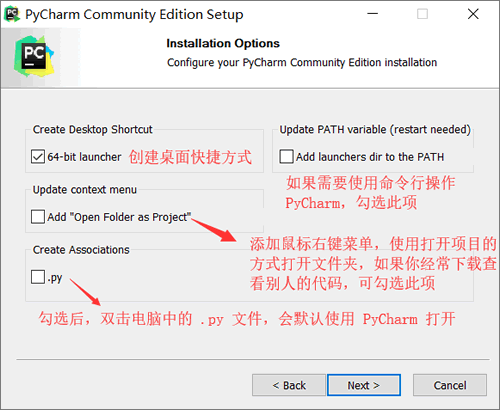
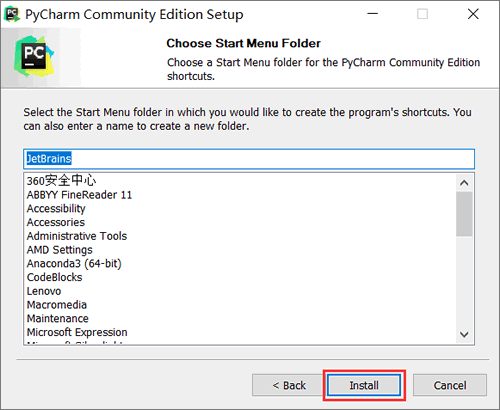
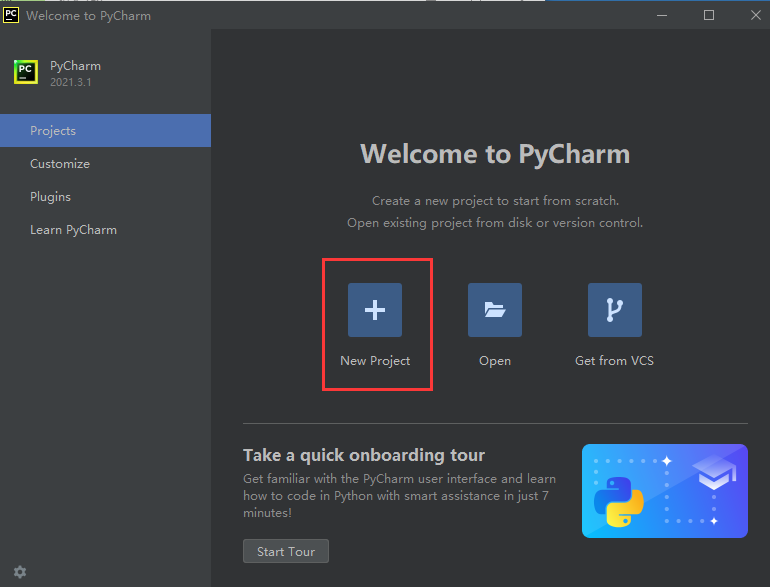
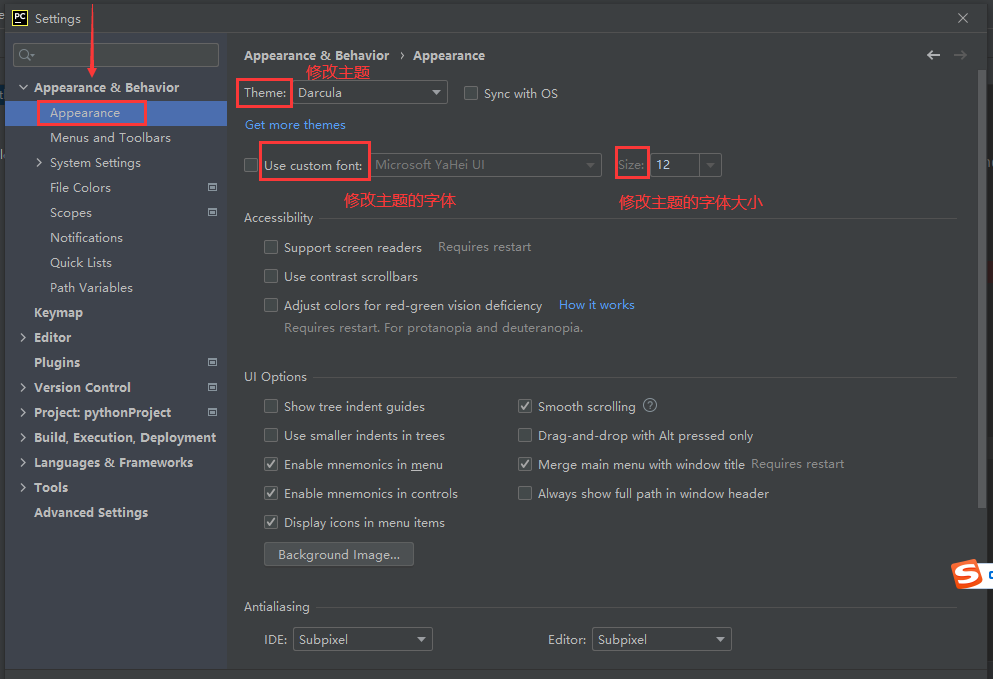
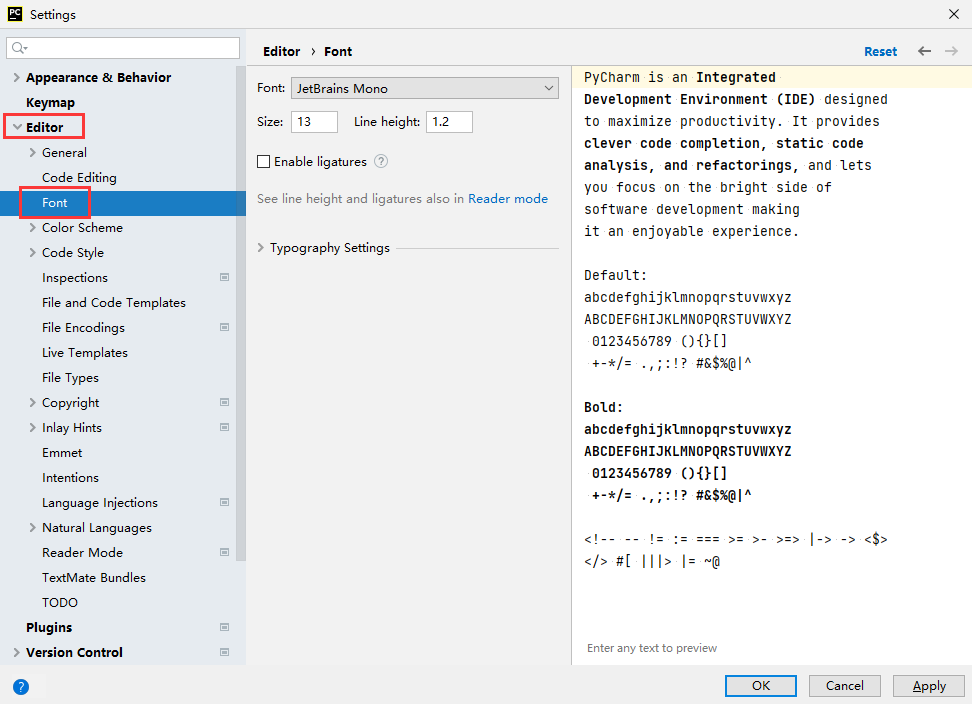
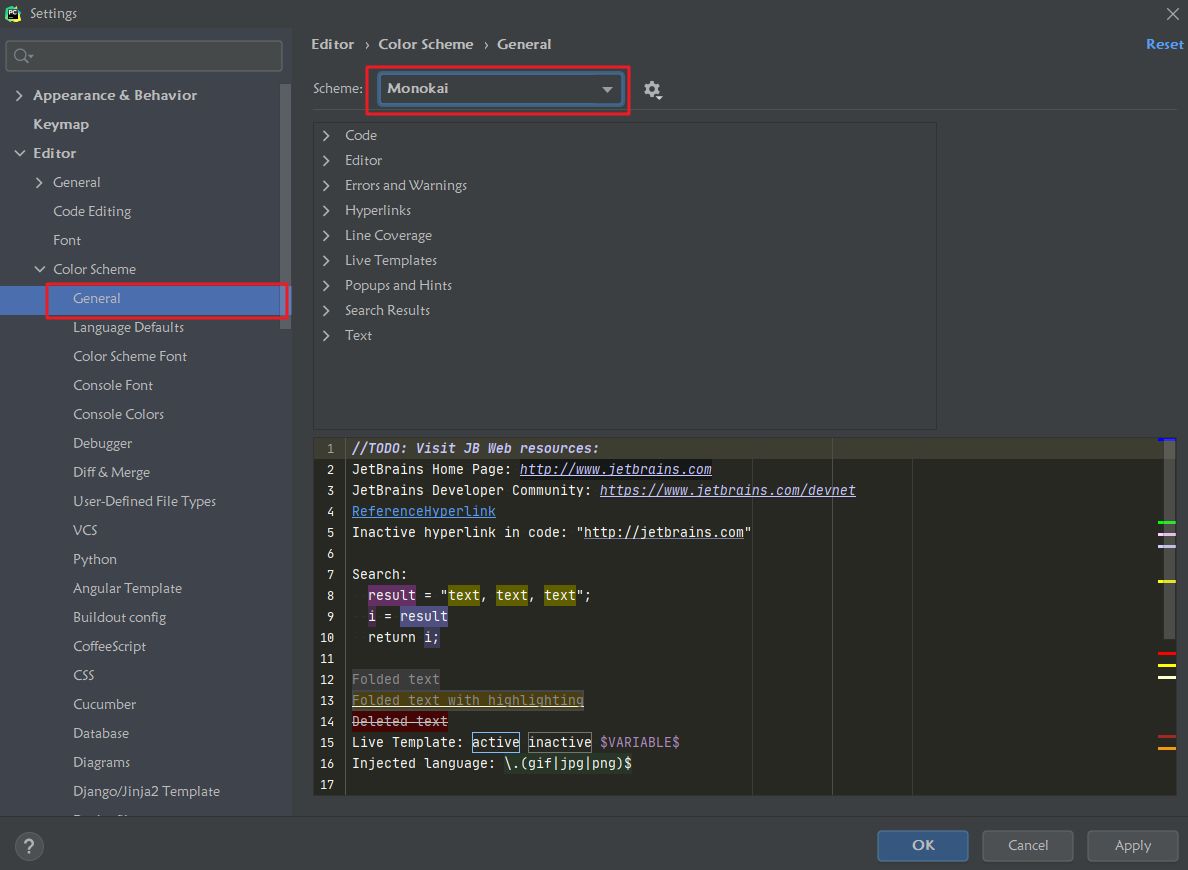
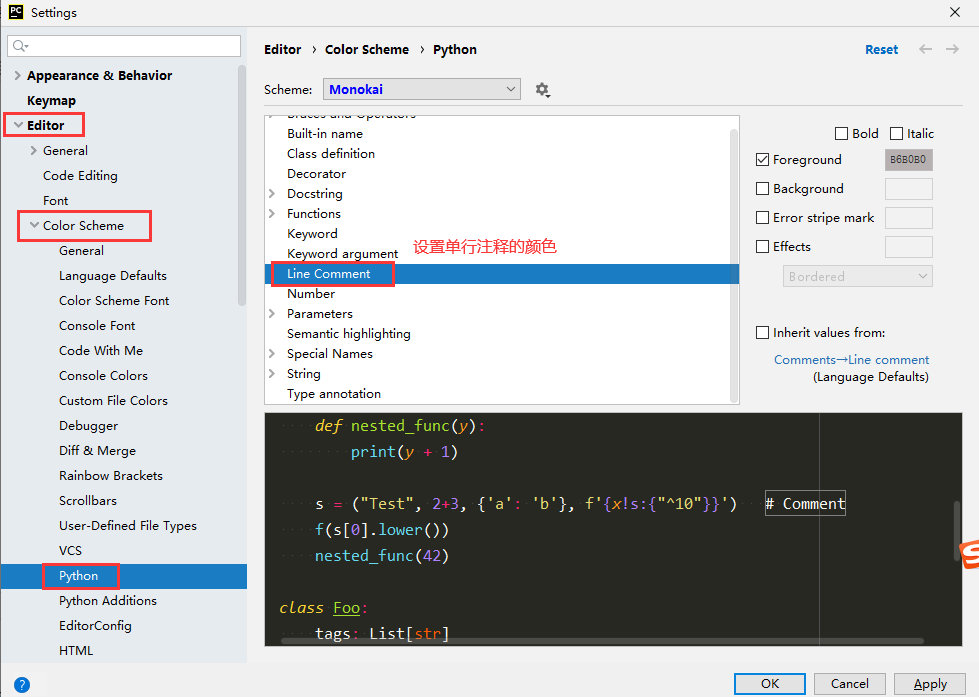
三. 调整PyCharm的主题和字体
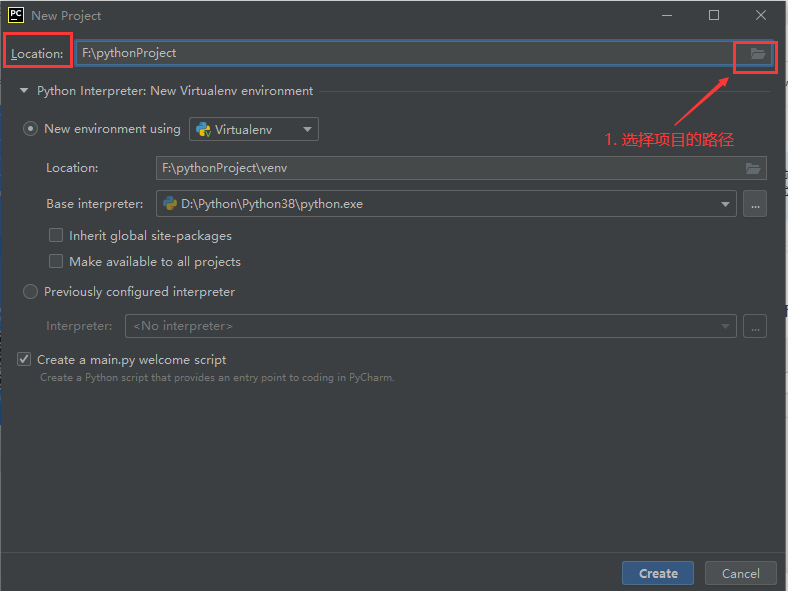
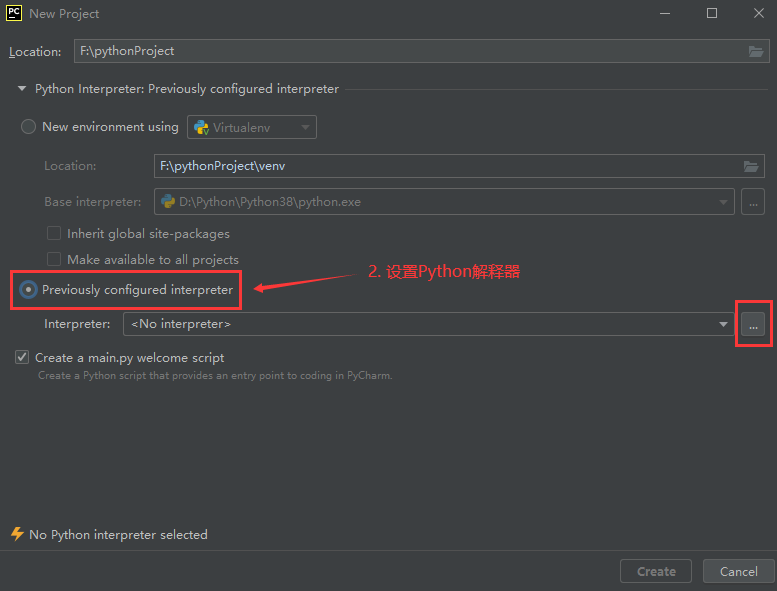
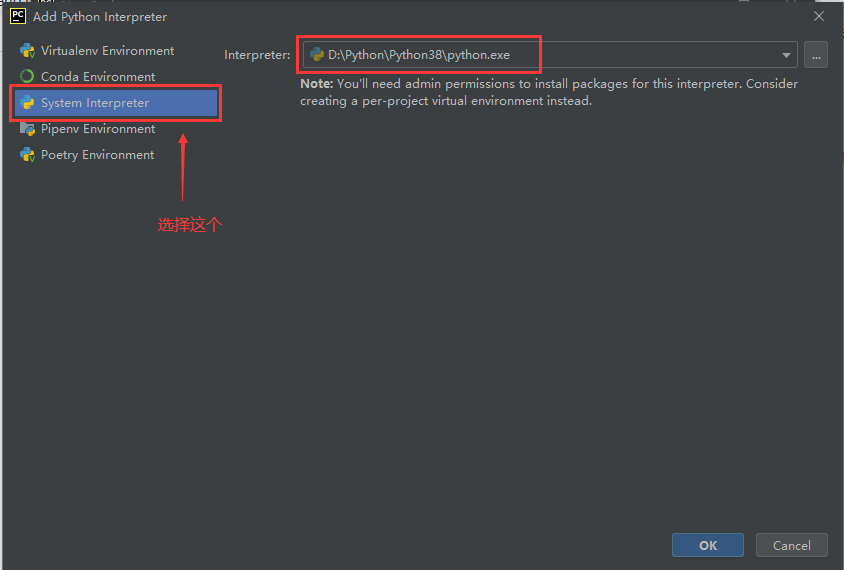
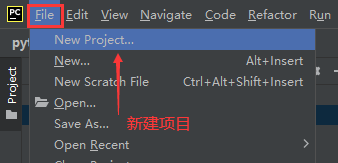
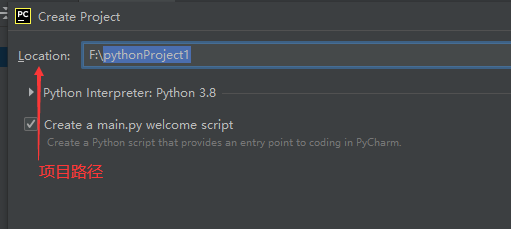
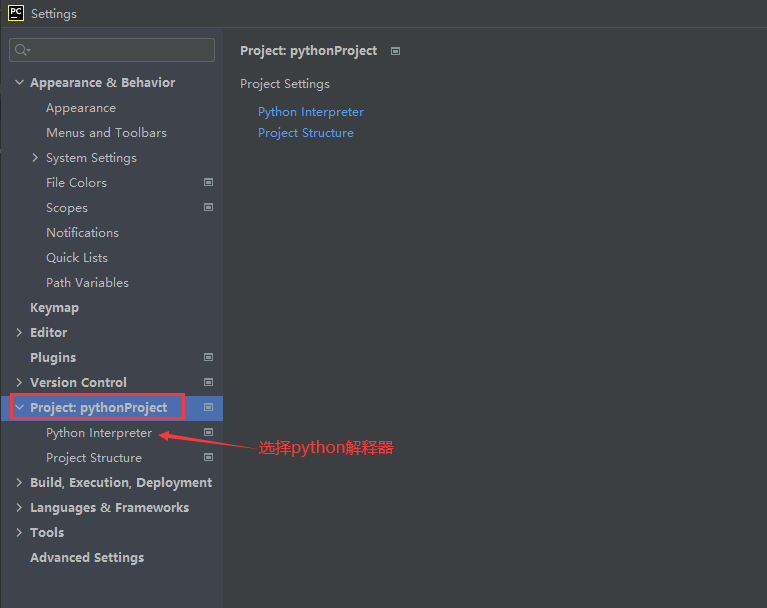
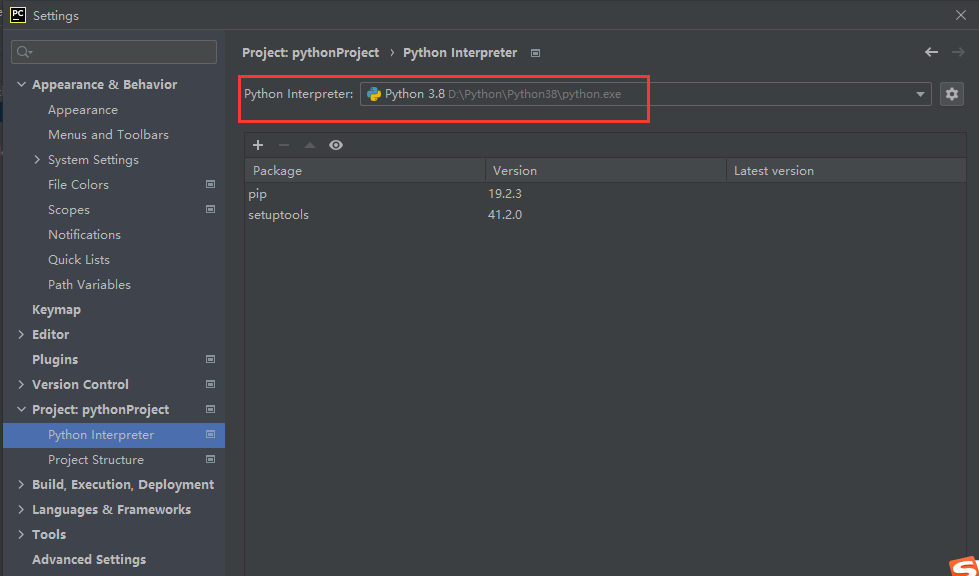
四. 新建项目
五. 运行项目
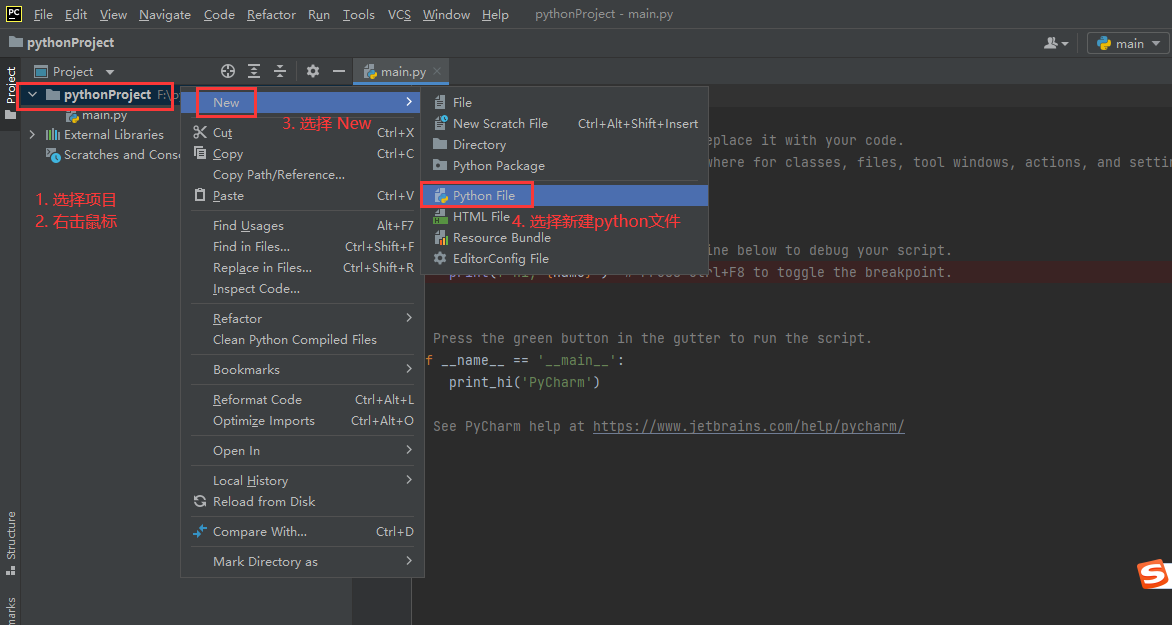
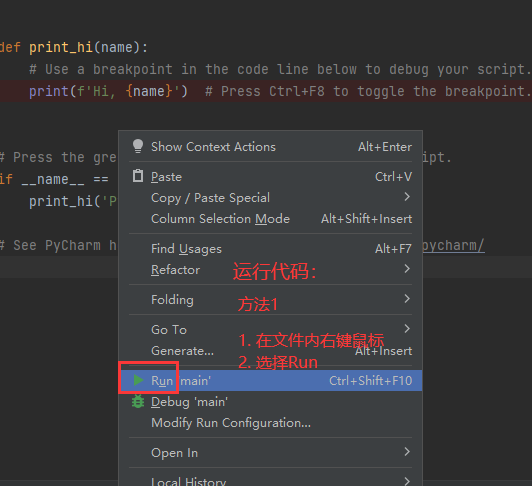

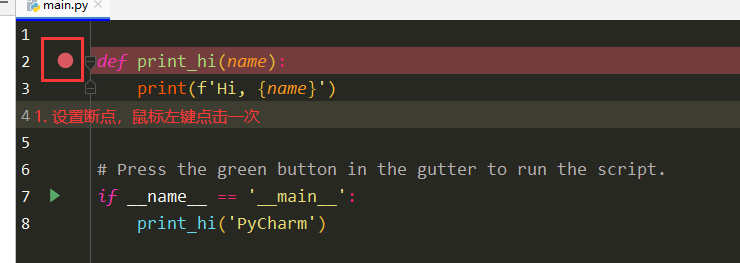
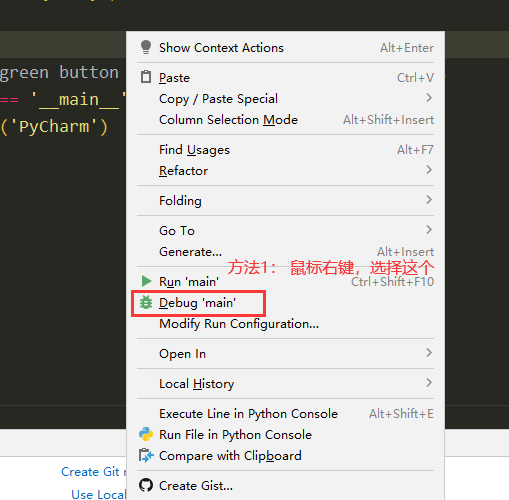
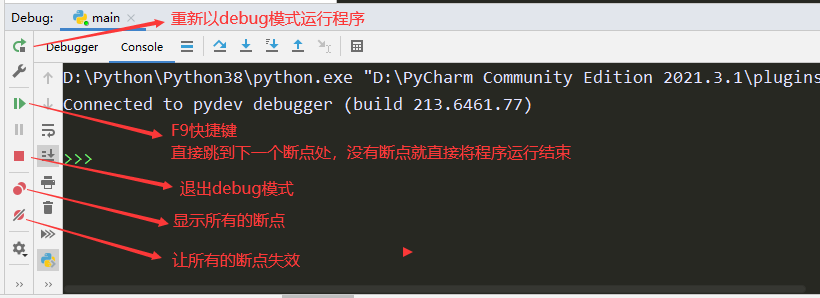
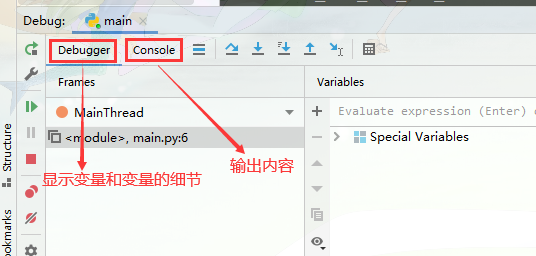
六. debug代码
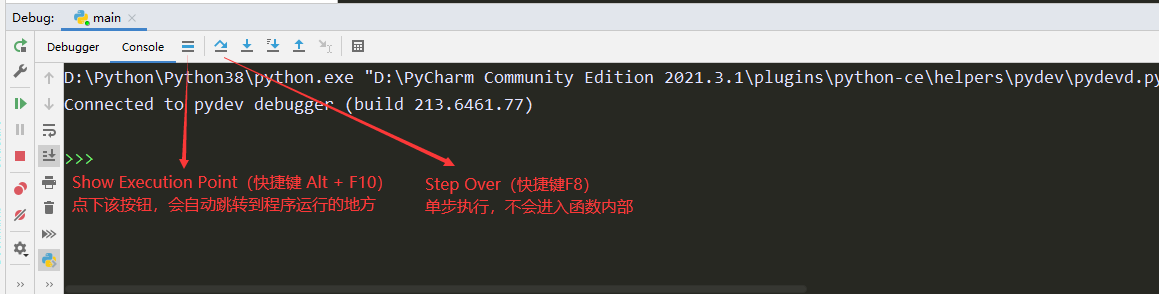
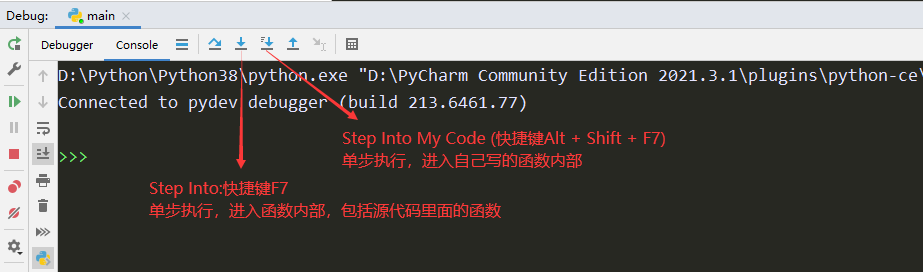
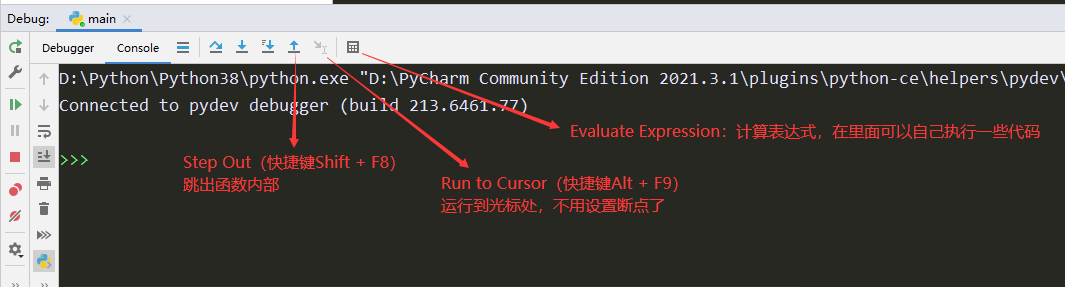
dubug的步骤:
按F8单步执行,要进入函数的时候按F7,要跳出函数的时候按shift + F8,按F9跳到下一个断点
七. 注释
1.单行注释 ( 快捷键 ctrl + / )
# 注释内容
代码
2.多行注释
"""
注释的内容
"""
八.导入Matplotlib、numpy、pandas
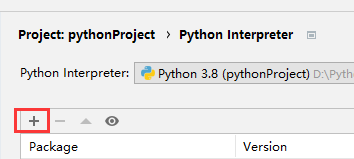
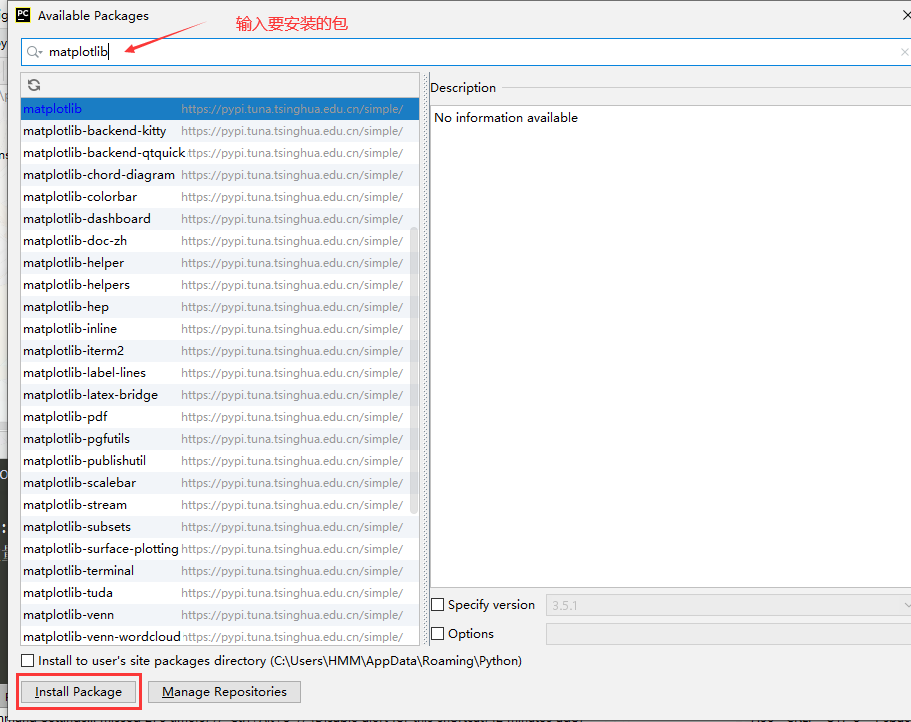
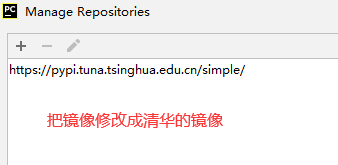
九.命名原则
1.小驼峰原则
第一个单词的首字母小写,第二个单词的首字母大写,例如firstName
2.大驼峰原则
每个单词的首字母都要大写,例如FirstName
十. 输入和输出
1. 输入
(1) input()让程序暂停运行,等待用户输入信息,获取用户输入后,会赋值给一个变量
(2) int()将字符串转换为整型
2. 输出
用print()输出
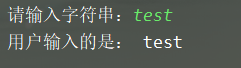
name = input("请输入字符串:")
print("用户输入的是:",name)
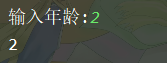
age = input("输入年龄:")
if int(age) > 0:
print(f"{age}")
else:
print(f"不合理")
十一. 数据类型
1.字符串
(1) 字符串是以单引号’或双引号”括起来的任意文本
'This is test'
"This is test"
(2) 字符串输出
方法1:
print('字符串 + 占位符' % 变量)
print('字符串 + 占位符1 + 占位符2' % (变量1,变量2))
占位符:
- 字符串:%s
- 整数:%d
- 浮点数:%f ( %.2f:显示小数点后2位数 )
方法2:
print(f"字符串 + {变量1}{变量2}")
age = 18
name = 'Tom'
weight = 120.123
student_id = 1
print( "我的名字是%s" % name )
print(f"我的名字是{name}")
print( "我的学号是%d" % student_id)
print(f"我的学号是{student_id}")
print( "我的体重是%.2f斤" % weight)
print( "我的体重是{weight}斤")
print( "我的名字是%s,今年%d岁" % (name, age))
print(f"我的名字是{name},今年{age}岁\n")

(3) 字符串的索引从0开始
(4) 字符串的常用操作
- 获取字符串的长度: len(字符串)
- 统计字符串2在字符串里面的出现次数: 字符串.count(字符串2)
- 从字符串中取出单个字符:字符串[索引]
- 获取字符串2第一次出现的索引: 字符串.index(字符串)
- 拆分字符串: 字符串.split()
- 用连接符合并字符串: “连接符”.join(字符串)
2.整型: int
3.浮点型: float
4.布尔型: bool
5.列表:list
(1) 列表在其它语言中通常叫做数组
(2) 列表可以存储不同类型的数据
(3) 列表用 [] 定义,数据之间用 “逗号,” 隔开
(4) 列表的索引从0开始,索引就是数据在列表中的位置编号,索引也称为下标
(5) 列表的常用操作
- 从列表中取值: 列表[索引]
- 获取数据第一次出现的索引: 列表.index(数据)
- 获取列表长度: len (列表)
- 在末尾追加数据: 列表. append (数据)
- 修改指定索弓|的数据: 列表[索引]=数据
- 删除末尾数据: 列表.pop
- 升序排序: 列表.sort ()
- 在指定位置插入数据: 列表.insert (索引,数据)
- 将列表2的数据追加到列表: 列表.extend (列表2)
- 删除第一个出现的指定数据: 列表.remove [数据]
- 删除指定索弓|数据: 列表.pop (索引)
- 清空列表: 列表.clear
- 统计数据在列表中出现的次数: 列表.count (数据)
- 降序排序: 列表.sort (reverse= True)
- 逆序 / 反转: 列表.reverse ()
name_list = ["zhangsan", "Lisi", "wangwu" ]
"""len(length长度)函数可以统计列表中元素的总数"""
list_len = len(name_list)
print ("列表中包含%d个元素" % list_len)
"""count方法可以统计列表中某一个数据出现的次数"""
count = name_list. count ("zhangsan")
print("zhangsan出现了%d 次" % count)
"""取值和取索引"""
print (name_list[2])
"""知道数据的内容,想确定数据在列表中的位置"""
print (name_list . index("wangwu"))
"""修改"""
name_list[1] = "李四"
"""从列表中删除第一次出现的数据,如果数据不存在,程序会报错"""
name_list.remove("zhangsan")
print (name_list)
"""append 方法可以向列表的末尾追加数据"""
name_list . append("王小二")
"""insert方法可以在列表的指定索引位置插入数据"""
name_list . insert(1, "小美眉")
"""extend方法可以把其他列表中的完整内容,追加到当前列表的末尾"""
temp_list = ["孙悟空", "猪二哥","沙师弟"]
name_list . extend(temp_list)
print(name_list)
"""remove 方法可以从列表中删除指定的数据"""
name_list . remove ("wangwu")
"""pop方法默认可以把列表中最后一个元素删除"""
name_list . pop()
"""pop方法可以指定要删除元素的索引"""
name_list . pop(3)
"""clear 方法可以清空列表"""
name_list. clear()

(6) 列表的循环
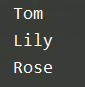
name_list = [ 'Tom','Lily','Rose']
i = 0
while i < len(name_list):
print(name_list[i] )
i = i + 1
6.元组: tuple
(1) 元组用**()**定义
(2) 元组里面的数据不能修改
(3) 元组表示多个元素组成的序列,数据之间使用 “逗号,” 分隔
(4) 元组可以存储不同的数据类型
(5) 元组的索引从0开始,索引就是数据在元组中的位置编号
(6) 元组中只包含一个元素时,需要在元素后面添加”逗号,”
info_tuple1 = () # 创建空元组
info_tuple2 = (10, ) # 元组中只包含一个元素时,需要在元素后面添加逗号
info_tuple3 = ("zhangsan", 18, 1.75)
(7) 元组的常用操作
- 根据索引从元组中取值:元组[索引]
- 获取元组的长度:len(元组)
- 获取数据在元组中出现的次数:元组.count(数据)
- 获得数据在元组中第一次出现的索引:元组.index(数据)
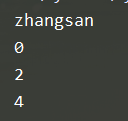
info_tuple = ("zhangsan", 18, 1.75, "zhangsan")
print(info_tuple[0]) # 取值
print (info_tuple. index ("zhangsan")) #已经知道数据的内容,希望知道该数据在元组中的索引
print (info_tuple. count ("zhangsan")) # 疏计计数
print (len(info_tuple)) # 统计元组中包含元素的个数
注: 列表和元组的转换
- 使用list函数可以把元组转换成列表:list(元组)
- 使用tuple函数可以把列表转换成元组:tuple(列表)
7.集合: set
(1) 集合用**{}或者set()**定义,如果创建空集合只能用set()
(2) 集合的数据是无序的,不支持下标访问
(3) 集合没有重复元素
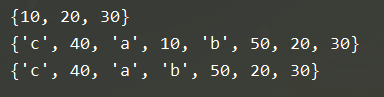
test1 = {"java","c"}
test2 = {1,2,3,4}
(4) 集合的常见操作
- 添加数据:add()
- 添加的数据是序列: update()
- 删除数据:remove()
s1 = {10,20}
s1.add(30)
print(s1)
s1.update([40,50])
s1.update('abc')
print(s1)
s1.remove(10)
print(s1)
8.字典:dict
(1) 字典用**{}**定义
(2) 字典使用键值对存储数据,键值对之间使用 “逗号,” 分隔
- 键key是索引
- 值value 是数据
- 键key和值value之间使用 “冒号:” 分隔
- 键必须是唯一的
- 键只能是字符串、数字或者元组
- 值可以取任何数据类型
(3) 字典同样可以用来存储不同的数据类型
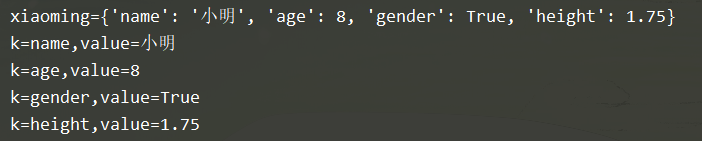
(4) 循环遍历字典
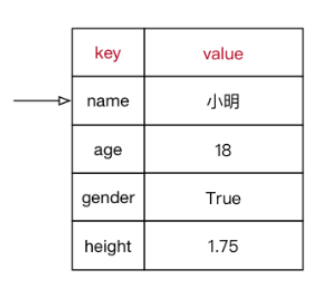
xiaoming = {"name":"小明",
"age":8,
"gender":True,
"height": 1.75}
print(f"xiaoming={xiaoming}")
for k in xiaoming.keys(): # 遍历字典
print(f"k={k},value={xiaoming[k]}")
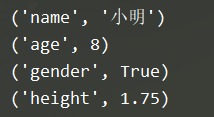
(5) 遍历字典的元素
xiaoming = {"name":"小明",
"age":8,
"gender":True,
"height": 1.75}
for item in xiaoming.items():
print(item)
(6) 遍历字典的键值对
xiaoming = {"name":"小明",
"age":8,
"gender":True,
"height": 1.75}
for key,value in xiaoming.items():
print(f"key={key},value={value}")

(7) 列表里面嵌套字典
"""将多个字典放在一个列表中"""
card_list = [{"name": "张三",
"qq":"12345",
"phone":"110"},
{"name":"李四",
"qq" :"54321",
"phone":"10086"}
]
for card_info in card_list:
print (card_info)

(8) 字典是一个无序的数据集合,使用print函数输出字典时,通常输出的顺序和定义的顺序是不一致的
(9) 字典不支持下标访问,只能按照键的名字去找值
(10) 字典的常用操作
- 获取字典的键值对数量:len(字典)
- 获取所有key列表:字典.keys()
- 获取所有value列表:字典.values()
- 获取字典的所有元素 / 所有键值对:字典.items()
- 根据key值查找:字典[key] (key不存在会报错)
- 根据key值查找:字典.get(key) (key不存在不会报错)
- 删除指定键值对:字典.pop(key)
- 随机删除一个键值对:字典.popitem()
- 清空字典:字典.clear()
- 字典[key] = value:如果key存在,修改数据,如果key不存,新建键值对
- 字典.setdefault(key, value):如果key存在,不会修改数据,如果key不存在,新建键值对
- 将字典2的数据合并到字典:字典.update(字典2)
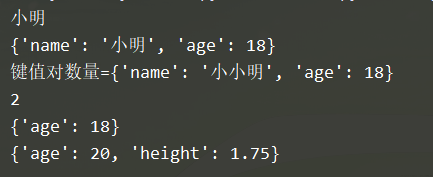
xiaoming_dict = {"name": "小明"}
print (xiaoming_dict ["name"]) #在取值的时候,如果指定的key不存在,程序会报错!
xiaoming_dict["age"] = 18 # 如果key不存在,会新增键值对,如果key已经存在,会修改已经存在的键值对
print(xiaoming_dict)
xiaoming_dict["name"] = "小小明"
print(f"键值对数量={xiaoming_dict}")
print(len(xiaoming_dict)) # 统计键值对数量
xiaoming_dict.pop ("name" ) # 在删除指定键值对的时候,如果指定的key不存在,程序会报错
print (xiaoming_dict)
temp_dict = {"height": 1.75, "age": 20} #注意:如果被合并的字典中包含已经存在的键值对,会覆盖原有的键值对
xiaoming_dict.update(temp_dict ) # 合并字典
print(xiaoming_dict)
xiaoming_dict.clear( ) # 清空字典
十二.if 和 else的语法
if 条件1:
代码
elif 条件2:
代码
else:
代码
注:
1.属于if条件的代码要缩进四个空格,属于elif条件的代码要缩进四个空格,属于else的代码要缩进四个空格
2.if语句以及缩进部分是一个完整的代码块,else语句以及缩进部分是一个完整的代码块
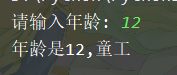
age = int(input( '请输入年龄: '))
if age < 18:
print(f"年龄是{age},童工")
elif 18 <= age <= 60:
print(f"您的年龄是{age},合法工龄")
else:
print(f"您的年龄是{age},可以退休")
十三.循环
(1) while循环
定义计数器
while 条件:
在循环内部执行的代码
改变计数器的值
注:
1.属于while循环的代码要缩进四个空格
3.while语句以及缩进部分是一个完整的代码块
i = 1
while i <= 3:
print( f"{i}")
i = i + 1
print( f"{i}")

(2) for循环
for 变量 in 列表:
代码
str1 = 'ihem'
for i in / not in str1:
if i == 'e':
print('遇到e不打印')
break
print(i)

注:
1.属于for循环的代码要缩进四个空格
2.break某一条件满足时,退出循环,不再执行后续重复的代码
3.cont inue某一条件满足时,不执行后续重复的代码
4.break和continue只针对当前所在循环有效
十四.range()函数
1.range(start,end, step):左闭右开[start,end),生成从start到end-1的数字,不包含end,步长为step
for i in range(1, 4, 1):
print(i)

2.range(num):生成从0到num-1的数字 (range函数只有一个参数的时候)
for i in range(4):
print(i)

3.使用range()创建数字列表
list()函数将range()的结果直接转换成列表
number1 = list(range(1, 4))
print(number1)
number2 = list(range(4))
print(number2)
number3 = list(range(1,10,2))
print(number3)

十五.列表解析 / 列表生成式
列表解析:把for循环和创建新元素的代码合并成一行
square = [value * 2 for value in range(1,5)] # 把1到4的数字提供给表达式value*2,
print(f"square={square}")

等价于
square = []
for value in range(1,5):
square.append(value * 2)
print(f"square={square}")
十六.切片
1.切片适用:
字符串、列表、元组
2.切片的格式
(1) 字符串/列表/元组[开始索引:结束索引:步长]
(2) 切片的区间是左闭右开:[开始索引,结束索引),从开始索引到结束索引的前一位,不包括结束索引
(3) [ :结束索引]:省略开始索引,表示默认从索引0(第一个元素)开始
(4) [开始索引: ]:省略结束索引,表示默认到最后一个元素结束
(5) [开始索引:结束索引]:省略步长,表示步长默认是1
(6) [ : ]:省略开始索引和结束索引,表示复制列表,从第一个元素到最后一个元素
(7) [ : : step]:省略开始索引和结束索引,从第一个元素到最后一个元素,步长为step
(8) 如果步长是-1,表示从右向左切片
(9) 索引是负数:表示倒数第几个元素,-1表示倒数第一个元素,-3表示倒数第三个元素
(10) 开始索引是负数:表示从倒数第几个元素开始,是包括倒数第几个元素
(11) 结束索引是负数:表示到倒数第几个元素之前的元素,不包括倒数第几个元素,因为区间是左闭右开
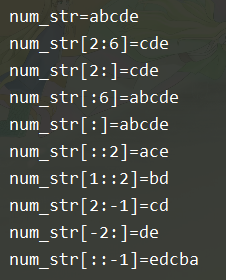
num_str = "abcde"
print(f"num_str={num_str}")
print(f"num_str[2:5]={num_str[2:5]}") # 从索引2到索引5,即第3个元素到第5个元素
print(f"num_str[2:]={num_str[2:]}") # 从索引2到最后一个元素,即第3个元素到最后一个元素
print(f"num_str[:5]={num_str[:5]}") # 从索引0到索引4,即从第1个元素到第5个元素
print(f"num_str[:]={num_str[:]}") # 从第1个元素到最后1个元素
print(f"num_str[::2]={num_str[::2]}") # 从第1个元素到最后1个元素,步长是2
print(f"num_str[1::2]={num_str[1::2]}") # 从索引1到最后1个元素,即从第2个元素到最后1个元素,步长是2
print(f"num_str[2:-1]={num_str[2:-1]}") # 从索引2到倒数第1个元素之前的元素,即从第3个元素到倒数第2个元素,不包括倒数第1个元素
print(f"num_str[-2:]={num_str[-2:]}") # 从倒数第2个元素到最后1个元素
print(f"num_str[::-1]={num_str[::-1]}") # 从右向左切片
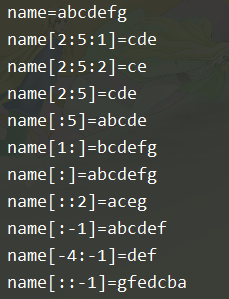
name = "abcdefg"
print(f"name={name}")
print(f"name[2:5:1]={name[2:5:1]}")
print(f"name[2:5:2]={name[2:5:2]}")
print(f"name[2:5]={name[2:5]}")
print(f"name[:5]={name[:5]}")
print(f"name[1:]={name[1:]}")
print(f"name[:]={name[:]}")
print (f"name[::2]={name[::2]}")
print(f"name[:-1]={name[:-1]}")
print (f"name[-4:-1]={name[-4:-1]}")
print(f"name[::-1]={name[::-1]}")
十七.函数
1.函数的定义
def 函数名
函数封装的代码
2.函数的调用
通过函数名调用函数,如果不主动调用函数,函数是不会执行的
注意: 函数定义要放在函数调用前面
3.函数的注释
函数的注释要写在定义函数的下方
注意: 函数定义的上方要有两个空行
def say_hello():
"""
打招呼
"""
print("hello")
say_hello()
4.函数的返回值
函数返回多个值:
(1) return a,b 返回多个数据的时候,默认是元组类型
(2) return后面可以连接列表、元组或者字典,从而返回多个值
(3) 使用元组可以让函数一次返回多个结果,如果函数的返回值是元组,括号可以省略
def measure():
temp = 39
wetness = 50
return temp, wetness # 省略了元组的括号,本来是 return (temp, wetness)
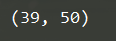
result = measure( )
print ( result)
(4) 如果函数返回值是元组,同时希望单独处理元组中的元素,可以使用多个变量,一次接收函数的返回结果,注意:变量的数量需要和元组中的元素数量保持一致
def measure():
temp = 39
wetness = 50
return temp, wetness # 返回值是元祖,所以省略了元祖的括号
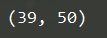
gl_temp,gl_wetness = measure()
print(gl_temp)
print(gl_wetness )
5.不定长参数 / 可变参数
(1) 有时可能需要一个函数能够处理的参数个数是不确定的,这个时候,就可以使用多值参数
(2) python中有两种多值参数:
参数名前增加 * :接收元组
参数名前增加 ** : 接收字典
(3) 一般在给多值参数命名时,习惯使用以下两个名字
*args:传进来的所有参数都会被args变量收集,它会根据传进参数的位置合并为一个元组,args是元组类型
**kwargs:存放字典参数,记忆键值对参数
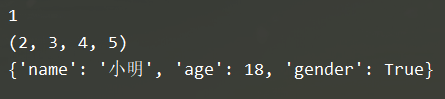
def demo(num,*args, **kwargs):
print( num )
print(args )
print( kwargs)
demo(1, 2, 3, 4, 5, name="小明",age=18, gender=True )
6.元组和字典的拆包
(1) 在调用带有多值参数的函数时,如果希望:
- 将一个元组变量,直接传递给args
- 将一个字典变量,直接传递给kwargs
(2) 就可以使用拆包,简化参数的传递,拆包的方式是:
- 在元组变量前,增加 *
- 在字典变量前,增加 **
def demo (*args,**kwargs):
print(f"元组变量args={args}")
print (f"字典变量kwargs={kwargs}")
nums = (1, 2, 3) # 元组变量
dict = {"name": "小明", "age": 18} # 字典变量
demo(*nums, **dict)

十八.变量的引用
1.变量和数据是分开存储的,数据保存在内存中,变量保存着数据在内存中的地址
2.变量中记录数据的地址,就叫做引用
3.如果变量已经被定义,当给一个变量赋值的时候,本质上是修改了数据的引用,变量不再对之前的数据引用,而是改为对新赋值的数据引用
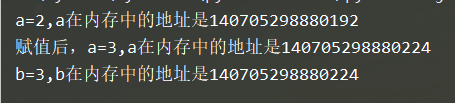
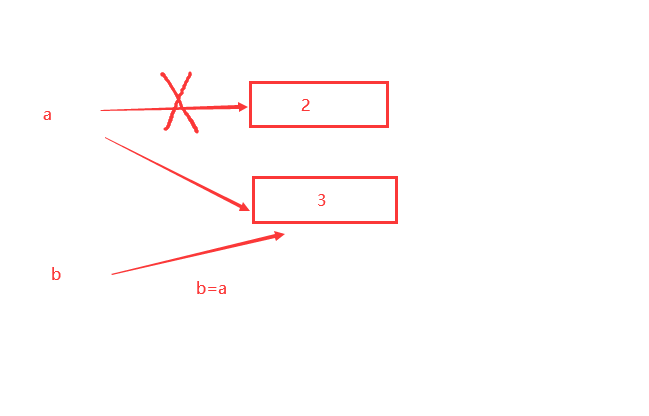
a = 2
print("a=%d,a在内存中的地址是%d" % (a,id(a)))
a = 3
print("赋值后,a=%d,a在内存中的地址是%d" % (a,id(a)))
b = a
print("b=%d,b在内存中的地址是%d" % (b,id(b)))
十九.可变类型和不可变类型
(1) 可变类型:内存中的数据能直接修改
(2) 可变类型有:
- 列表
- 字典
- 集合
(3) 如果给可变类型的变量赋值了一个新的数据,引用会被修改:变量不再对之前的数据引用,变量改为对新赋值的数据引用
(4) 不可变类型:内存中的数据不能直接修改
(5) 不可变类型有:
- 数字型(int、bool、float等)
- 字符串
- 元组
二十.局部变量和全局变量
1.局部变量
(1) 局部变量的定义
- 局部变量是在函数内部定义的变量,只能在函数内部使用
- 函数执行结束后,函数内部的局部变量,会被系统回收
- 不同的函数,可以定义相同的名字的局部变量,但是彼此之间不会产生影响
(2) 局部变量的作用
在函数内部使用,临时保存函数内部需要使用的数据
(3) 局部变量的生命周期
- 所谓生命周期就是变量从被创建到被系统回收的过程
- 局部变量在函数执行时才会被创建
- 函数执行结束后局部变量被系统回收
- 局部变量在生命周期内,可以用来存储函数内部临时使用到的数据
2.全局变量
(1) 全局变量是在函数外部定义的变量,所有函数内部都可以使用这个变量
(2) 为了保证所有的函数都能够正确使用到全局变量,应该将全局变量定义在其他函数的上方
(3) 全局变量名前应该增加g_ 或者g1_的前缀
(4) 在函数内部不允许直接修改全局变量的值,如果在函数内部使用赋值语句修改全局变量的值,只是相当于定义了一个局部变量
#全局变量
num = 10
def demo1():
# 是不允许直接修改全局变量的值
# 如果使用赋值语句,会在函数内部,定义一个局部变量
num = 99
print ("demo1 ==> %d" % num)
def demo2():
print("demo2 ==> %d" % num)
demo1()
demo2()
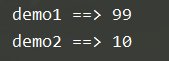
(5) 如果在函数中需要修改全局变量,需要使用global进行声明
#全局变量
num = 10
def demo1():
#希望修改全局变量的值.使用global 声明一下变量即可
#global关键字会告诉解释器后面的变量是--个全局变量
#再使用赋值语句时,就不会创建局部变量
global num
num = 99
print("demo1 ==> %d" % num)
def demo2() :
print("demo2 ==> %d" % num)
demo1()
demo2()

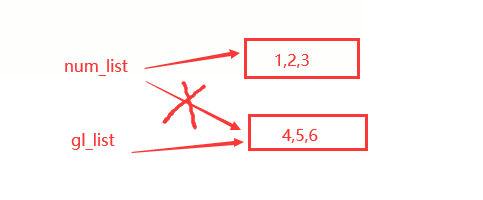
def demo (num_list):
print ("函数内部的代码")
#在函数内部,针对参数使用赋值语句,不会修改到外部的实参变量
num = 100
num_list = [1, 2, 3]
print(num_list)
print("函数执行完成后")
gl_list = [4, 5, 6]
demo(gl_list)
print(gl_list)

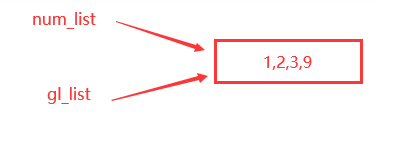
def demo(num_list):
print ("函数内部的代码")
#使用方法修改列表的内容
num_list. append(9)
print(num_list)
print ("函数执行完成")
gl_list = [1,2,3]
demo(gl_list)
print(gl_list)
注意:
函数执行时,需要处理变量时会:
1.首先查找函数内部是否存在指定名称的局部变量,如果有,直接使用
2.如果没有,查找函数外部是否存在指定名称的全局变量,如果有,直接使用
3.如果还没有,程序报错!
二十一.模块
1.导入模块的方式
- import 模块名
- import 模块名1,模块名2,…
- from 模块名 import 功能名
- from 模块名 import 功能名1,功能名2,…
- from 模块名 import *
- import 模块名 as 别名
- from 模块名 import 功能名 as 别名
别名要符合大驼峰原则
2.调用功能
模块名.功能名()
3.制作自定义模块
python中每个文件都可以作为一个模块,模块的名字就是文件的名字
(1) 只在当前文件中执行测试代码,其它导入该模块的文件不执行测试代码
(2) 测试代码格式:
if __name__ == '__main__':
调用模块里面的函数
def testA(a, b): # 在 my_module1.py文件中定义模块和测试模块
print(a + b)
if __name__ == '__main__':
testA(1,1)
(4) 调用模块
import my_module1
my_module1.testA(1,1)
二十二.包
1.导入包
(1) 方法1
导入包:import 包名.模块名
调用:包名.模块名.目标
(2) 方法2
导入包:
1.from 包名 import *
2.在包内部的init.py文件添加all == [],控制允许导入的模块列表
调用:模块名.目标
""" 新建一个包my_package,在包里面添加模块my_module.py,模块内代码如下:"""
def info_print():
print("test")
方法1:
"""导入包里面的模块"""
import my_package.my_ module
"""调用模块里面的方法"""
my_package.my_ module.info_print()
方法2:
在__init__.py文件中添加__all__ = []
"""导入包里面的模块"""
from my_package import *
"""调用模块里面的方法"""
my_module.info_print( )
二十三.类和对象
1.定义类:类名要符合大驼峰原则 (首字母大写)
class 类名():
def 函数(self,参数列表):
pass
类里面定义的函数必须有self,self是调用该函数的对象
类里面的代码是:class下面缩进的代码
class Person:
def run(self):
print("调用Person类里面的run方法")
xiaoming = Person()
xiaoming.run()

2.创建对象(实例对象)
对象名 = 类名()
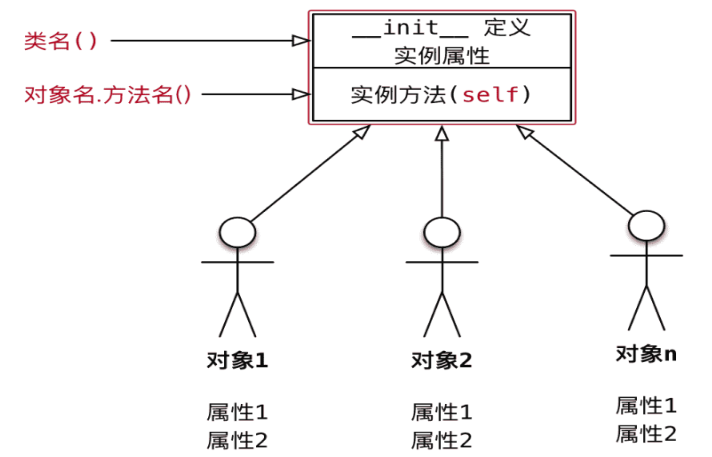
- 创建对象的动作叫作实例化
- 对象的属性叫做实例属性
- 对象调用的方法叫做实例方法
- 在程序执行的时候,对象可以通过self.访问自己的属性和调用自己的方法
3.self
self:是调用该函数的对象,哪一个对象调用的函数,self就是哪一个对象的引用
4.调用类里面的函数
对象名.函数()
5.获取属性(实例属性)
(1) 类外面获取对象属性
对象名.属性名
(2) 类里面获取对象属性
self.属性名
属性要封装在类的内部
在类的外部,通过 “变量名.” 访问对象的属性和方法
在类封装的方法中,通过 “self.” 访问对象的属性和方法
6.初始化方法 __init__方法
__init__方法是专门用来定义一个类具有哪些属性的方法
__init__在创建对象的时候会自动被调用
(1) 当使用类名()创建对象时,会自动执行以下操作:
1.在内存中为对象分配空间和返回对象的引用:使用__new__方法
2.为对象的属性设置初始值:调用初始化方法(__init__方法)
(2)不带形参的__init__方法
- 在__init__方法内部定义属性:self.属性名 = 初始值
- 定义属性之后,再使用类名创建的对象都会拥有该属性
格式:
class Cat:
def __init__ (self):
pass
对象名 = 类名() # #使用类名( )创建对象的时候,会自动调用初始化方法__init__
注: init(self) 中的self参数,不需要开发者传递,python解释器器会自动把当前的对象引用传递过去
class Cat:
def __init__ (self):
print("这是个初始化方法" )
self.name = "Tom" # 定义用Cat类创建的对象都有name属性
def eat(self): # slef是调用方法的对象,即 tom
print(f"{self.name}")
tom = Cat() # #使用类名( )创建对象的时候,会自动调用初始化方法__init__
tom.eat()

(3) 带形参的init()方法
如果希望在创建对象的同时,就设置对象的属性:
把希望设置的属性值,定义成__init__方法的参数
在__init__方法内部定义属性: self.属性 = 形参
在创建对象时,使用类名(属性1的值,属性2的值,…)调用
class Cat:
def __init__ (self, name):
print("这是个初始化方法" )
self.name = name # 接收传递的参数
def eat(self): # slef是调用方法的对象,即 tom
print(f"{self.name}")
tom = Cat("Tom") # #使用类名( )创建对象的时候,会自动调用初始化方法__init__
tom.eat()

7.__str__方法
(1) __str__方法可以让print输出对象的时候,输出的是__str__方法的返回值
(2) 如果没有__str__方法,当用print输出对象的时候,是输出对象是由哪个类创建的和对象在内存中的地址
class Cat:
def __init__ (self, name):
self.name = name
tom = Cat("Tom")
print(tom)

class Cat:
def __init__ (self, name):
self.name = name
def __str__(self):
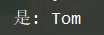
return "是: %s" % self.name
tom = Cat("Tom")
print(tom)
class Person:
def __init__(self, name, weight):
print("__init__方法")
self.name = name
self.weight = weight
def __str__(self):
return "__str__方法:%.2f斤" % (self .weight)
def run(self):
print("run方法:%s跑步" % self.name )
xiaoming = Person("小明", 75)
xiaoming.run( )
print(xiaoming)

8.私有属性和私有方法
(1) 定义私有属性:在属性前面增加两个_
(2) 定义私有方法:在方法前面增加两个_
(3) 对象不不能访问私有属性和私有⽅方法,在类的外部访问不到私有属性和私有方法
(4) 子类⽆无法继承⽗父类的私有属性和私有⽅方法
(5) 获取私有属性: 定义函数get_xx
(6) 修改私有属性的值: 定义函数set_xx
class Women :
def __init__ (self, name):
self.name = name
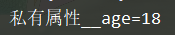
self.__age = 18 # 私有属性
print(f"私有属性__age={self.__age}")
def __secret(self): # 私有方法
print(f"年龄是{self.__age}")
xiaofang = Women("小芳")
class Women :
def __init__ (self):
self.__age = 8 # 私有属性
print(f"私有属性__age={self.__age}")
def set_age(self): # 修改私有属性
self.__age = 1
print(f"修改后私有属性__age={self.__age}")
def get_age(self): # 获取私有属性
return self.__age
xiaofang = Women()
xiaofang.set_age()
age = xiaofang.get_age()
print(f"返回的私有属性__age={age}")

二十四.类属性和类方法
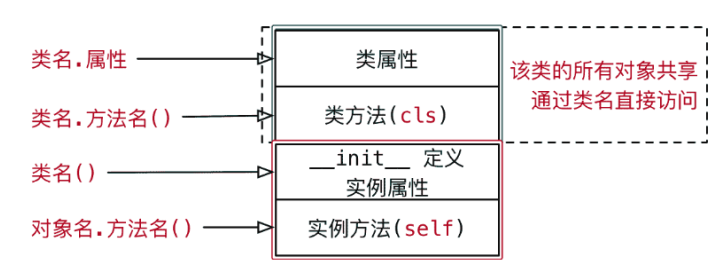
1.概念
- 类是一种特殊的对象,”class 类名”定义的类是类对象
- 类对象在内存中只有一份,一个类可以创建多个实例对象
- 类对象可以拥有自己的属性和方法,称为类属性和类方法
- 通过”类名.”可以访问类属性和调用类方法
2.类属性
类属性用来记录和类相关的特征
class Tool(object):
count = 0 # 类属性
def __init__ (self, name):
self.name = name # 对象的属性,即 对象的实例属性
Tool. count = Tool. count + 1
tool1 = Tool("斧头")
tool2 = Tool("榔头")
print(f"类属性Tool.count={Tool.count}")

二十五.面向对象三大特性
1.封装是把属性和方法封裝到一个类里面
2.继承实现代码的重用,相同的代码不需要重复的编写
3.多态不同的对象调用相同的方法,产生不同的结果
二十六.继承
1.单继承
(1) 继承:子类拥有父类以及父类的父类中封装的所有非私有属性和非私有方法
(2) 格式:
class 子类名(父类名):
pass
(3) 方法的重写
- 当父类的方法不能满足子类需求时,子类可以对方法进行重写
- 重写之后,在运行中只会调用子类中重写的方法,不会调用父类的同名方法
- 重写之后,子类调用父类的同名方法,在子类里面使用”super().函数()”
- 子类和父类具有同名属性和方法,默认使用子类的同名属性和同名方法
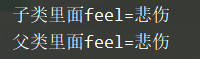
class Master(object) : # 父类
def __init__(self):
self.feel = "开心"
def make_cake(self):
print(f"父类里面feel={self.feel}")
class Prentice(Master): # 子类
def __init__(self):
self.feel = "悲伤"
def make_cake(self):
print(f"子类里面feel={self.feel}")
def father(self):
super().make_cake()
son = Prentice( )
son.make_cake()
son.father()
2.多继承
(1) 子类同时继承了多个父类
(2) 格式:
class 子类名(父类名1, 父类名2, ...):
pass
二十七.多态
(1) 子类重写父类的方法,不同子类的对象调用和父类同名的方法,可以得到不同的结果
(2) 实现步骤:
- 定义父类,并提供公共方法
- 定义子类,并重写父类方法
- 传递子类对象给调用者,可以看到不同子类执行效果不同
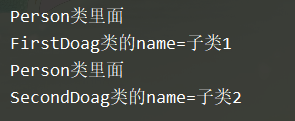
class Dog(object): # 定义父类
def __init__(self, name):
self.name = name
def game(self):
print(f"Dog类的name={self.name}")
class FirstDog(Dog): # 定义子类1
def game(self): # 重写父类的方法
print(f"FirstDoag类的name={self.name}")
class SecondDog(Dog): # 定义子类2
def game(self): # 重写父类的方法
print(f"SecondDoag类的name={self.name}")
class Person( object) :
def with_dog(self, dog): # 传入不同的对象,执行不同的代码,即不同的work函数
print("Person类里面")
dog.game()
firstDog = FirstDog("子类1")
secondDog = SecondDog("子类2")
person = Person( )
person.with_dog(firstDog)
person.with_dog(secondDog)
二十八.异常
1.捕获异常的格式:
try:
可能发生错误的代码
except 错误类型1:
发生错误类型1,执行的代码
except 错误类型2:
发生错误类型2,执行的代码
except Exception as result:
捕获未知错误,执行的代码
print( result)
else:
没有异常才会执行的代码
finally:
无论是否有异常,都会执行的代码


